October 21, 2018
Streaming music
I just read the column "Is your business streaming music for customers? That's breaking the law". I can't tell if this column's author is intentionally filing a propaganda piece or was just misled by sources, although now that I see from a FB preview that it's part of "Guardian Opinions" (something not at all clear from the page itself!), I lean toward the former. Several aspects of this piece are basically dishonest.
First, the idea that anything here is "costing the music industry $2.65bn a year" (a "fact" that they even pulled up for the subhed). Anytime you see a number like that, read it as "number that some industry reps made up to sound impressive". It invariably starts by assuming that everyone who is currently using something without paying would, if caught in enforcement, a) continue using it by b) paying for it at c) full retail rates. In addition to the dubious dollar amount, it also uses the word "costing" as if these were dollars that someone was paying, or dollars in a drawer that someone ran off with; in fact it represents "dollars that the industry would very much like to be flowing to them, which people aren't sending in their direction." You can argue that it's wrong, but it's not really the same thing, is it.
Then there's the spokesperson's analogy, which the author uncritically passes along: this is not like using a Netflix account to "open a cinema". This is using a Netflix account to project movies on mute onto the back wall for ambience. Again, maybe you still think that's not ok, but it's not such a "roll your eyes" obvious moment anymore, hmm?
Next the bit about 21m businesses "around the world". Hey, "the world" has some fairly variable policies when it comes to IP and fair use/fair dealing. Who exactly are we talking about here?
And finally, an interesting second number: near the bottom, the claim that the rights holders are "missing out on royalties of as much as $100m a month". That's only $1.2bn a year. Well under half the $2.65bn a year that this is supposedly "costing the music industry". Which meansand we already basically knew thisthat the content creators are already getting a lot of royalty money withheld from them by parasites elsewhere in the music food chain. Or, as this article's author might say, someone is "costing" them an awful lot of money, and it's not the people listening to their music.
"Without understanding, all of K-12 math education is much less valuable than a four-function calculator from the Dollar Store." --Matt Brenner
September 10, 2018
Another misleading infographic
Today we have another installment in our occasional series, "infographics that are not really telling the truth". This one is not actually quite as bad as I thought it was at first, but it does still tell a story that is wrong in a fairly important way.
The image, reproduced below, is from the Guardian's article "Sweden faces political impasse after inconclusive election".
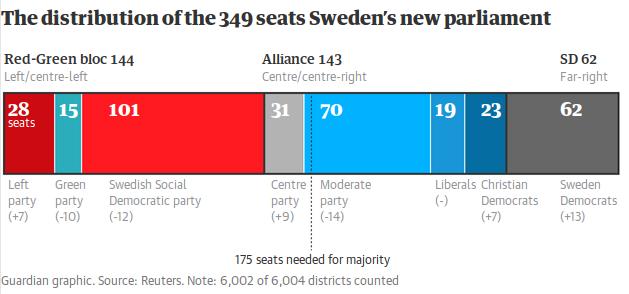
My first signal that something was weird was the dotted line down the middle. If that's representing 175 seats, why is it so far to the right? The red-green block plus the Centre Party make 175 exactly. And the bar that's ostensibly 31 seats is waaay less than half the one that is 70, and looks comparable to the one that's 19.
So I replotted it. The dashed line actually was in the right spot; I haven't moved it or any of the labels, nor have I changed any numbers---just the coloured bars, to reflect the actual proportions.
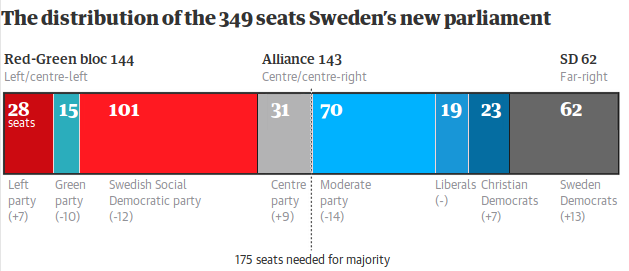
And indeed, it's not as bad as I thought; the problem I first identified really was the biggest error. But the important story of this infographic is: if the red-green bloc wants to form a government, who do they need to bring into their coalition (or at least acquire parliamentary support)? In the Guardian's graphic, the Centre Party clearly wouldn't be enough. But in fact, if they can be peeled off, that would be enough to form a (razor thin) government. Which is important.
"With absolutely no understanding of how narrative, plot, character development, or exposition work, Rand produces fiction that sounds like it was written in Urdu and translated into English with the least reliable free online translator available." --Ed Burmila
June 21, 2018
Telling a better story with a US map
The other day I was reading an article about
the (un)affordability of housing in the US. It contained the following image illustrating the hourly wages required to afford a 2-br rental in each state: ![]()
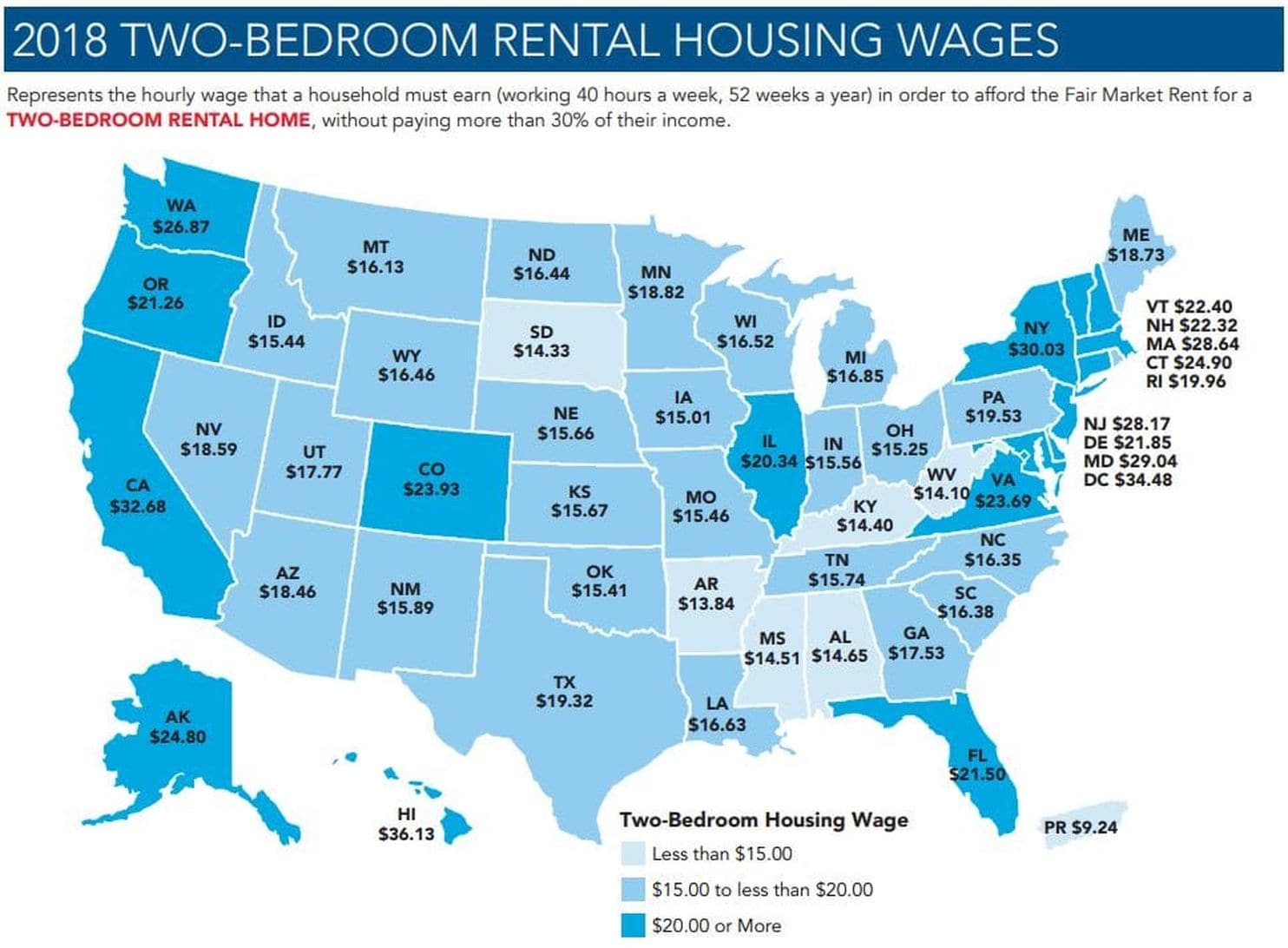
The NLIHC has putting these out for a while, so you might have seen it before even if you missed this year. The article in the Post was focused on DC specifically, of course, but the map was not really telling a very coherent story. The granularity of a state-by-state map for that is all wrong---the dark-blue (high cost) states were just the ones with bigger cities, mostly... though with some interesting exceptions that the map format completely hid from view. But there's Illinois at $20.34, about $5 more than the adjacent states. Isn't that really just Chicago, though? Cairo's not going to be too different from Paducah or Cape Girardeau, and Rockford's probably comparable to Janesville, and Freeport to Dubuque. Similarly for e.g. CO, maybe VA and the west coast states, and who can tell on the mid-Atlantic states? So: what if...
What if the map treated Chicago(-land) as a separate state from the rest of Illinois? And likewise for the other bigger cities? I knew that the US Census had made up clearly defined Metropolitan Statistical Areas (MSAs) for every city of any substantial size. So it actually seemed entirely plausible that you could take the top 40 or so MSAs and treat them as states, and then treat the "rest of the state" as a separate area to take an average of. I was quickly able to track down a listing of MSAs by population (thanks Wikipedia), but with only a bit more work I was able to track down the following, each in either .cvs or .xls (i.e.: easily computer processable) format:
- A list of each county or equivalent in the US, by name and with associated unique identifier called a FIPS code [0]
- A list of each MSA and µSA ("Micropolitan Statistical Area") in the US, with associated MSA code, and the FIPS code of every county in that MSA/µSA [1]
- A list of the population of every MSA in the US [2]
Perhaps even more importantly, I found an amazingly helpful post that pointed out that there was an .svg (i.e. not pixellated) map of the US, with county lines, on Wikimedia Commons, and that .svg file is fundamentally an editable text/xml format, and each county was helpfully marked with its FIPS code. Meaning it is super duper easy to make maps with counties colour-coded however you might want. Proof of concept: randomly colour each state, and the top-40 MSAs.

Yesss! This is perfect! You can see the multi-state-spanning populous MSAs pulled out separately from the constituent states. Now to pull in the data to actually visualise. Conveniently, the NLIHC show their work (mostly) and pointed me directly to
- A list of every county* in the US along with the "fair market rent" (FMR) in that area for 0-4 bedroom rental units, as well as the population of that area [3]
(* Ok, it turns out that the six New England states do have counties but mostly report their info by town instead, which are more like what we'd call townships elsewhere and they function as mini-counties. This particular list had them broken down to that level, which my map didn't, so I had to aggregate those first.)
So now I have per-county numbers, and a map-colouring system I'm itching to try. What would it look like if I assign colours to each county based on only that county's FMR? I adopted the same colouring scheme as the NLIHC map that inspired this project, with a slight extension: the "over $20" category I broke up into "under $30", "under $40", and "over $40", because at the county level some of the FMRs were over $60 (looking at you, Bay Area).*** The higher categories just used ever-darker shades of the same blue-green palette as the original map.
(*** The actual FMR numbers in the report are monthly rents, with ranges like "$850" or "$1100". To match the NLIHC maps, I multiply FMR by 12 and divide by 0.3 (to get "affordable" yearly rent), then divide by 52 (weeks in a year) and divide that by 40 (hours in a workweek) to get the required wage.)
All this yielded the following map:

Some spot-checking verifies that the underlying numbers are correct, and the more urban areas reflect a higher cost of living, withas expecteda much more uniformly cheap band across the Midwest and South. This sort of map is actually pretty common (and is, as I mentioned, surprisingly easy to make) to display county-by-county data. But in a lot of ways, it's now too noisy in the other direction to tell a coherent story. So I'll keep following through to produce the states-and-top-MSAs map that I thought would be interesting originally.
So here's the methodology: from that FMR data, which is per-county, I aggregate into 89** multi-county groups. Within that group, I do a weighted average: the 2BR FMR for a county, times the population of that county, added up for all the counties in the group and divided by the population of the MSA or rest-of-state region. Another way to think about this is, if you assign "this is my FMR for a 2BR rental" to every person in a region according to which county they're in, then take a regular average over the whole region. This gives each of the 89 regions an average FMR. Then, assign that average FMR back to every county in that region, and colour the map accordingly.
(** Every state except RI, plus the 40 top MSAs. Why not Rhode Island? Because the Providence MSA completely encompasses it! Interestingly, no other state was completely encompassed by top-40 MSAs, although New Jersey was close.)
By way of checking my work and my aggregations, I did want to run my code without the MSA stuff, just the states, to see if my numbers matched the NLIHC map that inspired all this. Verdict: not quite, but close:

There is not a consistent bias on the numberssome are slightly higher, some slightly lowerand I think it's because they were doing their averaging differently. (Note that California, Hawai`i, and DC are darker not because of a difference in numbers but because I'm colouring over-$30 wage requirements in an even darker colour than the original map.) I'll keep investigating that, but in the meantime this is certainly close enough to say that it's basically replicating the original work and is now ready for my intended upgrade. Et voilà:

And it's all there. First of all, there's the more coherent story that the Midwest and Deep South are broadly cheaper places to live than the rest of the country, camouflaged in the original map because of the substantial influence of large citiesChicago manages to pull up the statewide average by two levels, but overall, the vast majority of Illinois is relatively cheap to live in. Meanwhile the West Coast, Mountain West, and Southwest are all a bit more expensive to live in, even pulling out several expensive metro areas. California, even after pulling out six highly populous MSAs, is still, overall, a very expensive place to live (and two of those MSAs are in the over-$40 category, even spread over multiple counties). New England and the Mid-Atlantic also tell a more nuanced story. Rather than "here's a wide band of uniformly more expensive states", we see the Northeast Corridor itself, with multiple expensive or very expensive areas, surrounded by some moderately cheaper areas, like rest-of-New-York, and rest-of-Delaware. And the Providence metro area is, just as it has been for decades, a quiet little corner of (comparative) affordability (though to be fair, the by-state map basically does capture that part). But even on the states-minus-top-MSA map, Vermont, New Hampshire, Connecticut, and rest-of-Massachusetts still show up in the moderately expensive categorythe same colour they were in the by-state map, but the story is a stronger one since this is true even after factoring out some major confounds.
So that was yesterday's 12-hour project. Now that I've done that, I fully intend to keep some version of this program aroundI just can't get over how easy it was to make these maps, in the end, and I'm thinking I might even be able to work this into my gen ed intro programming class (this kind of data processing is central to the course, I had just assumed that maps would be too hard). Or, build a website: you submit a spreadsheet or CSV with by-county numbers, and I can hook you up with one of these state-and-MSA maps lickety-split. The number of MSAs is easy to adjust, and my initial guess of 40 feels about right; much less than that and the states are still dominating, and too many more and it just devolves into information overload that doesn't tell much of a story. Here's what it looks like with all the MSAs pulled out of the states:

So yeah, I think I'll stick with 40. But, many avenues for improvement from here, and of course, so much more data to visualise!
EDITED 22 Jun TO ADD: It took some massaging of the different Wikimedia map files (and the massaged result has been reuploaded to Wikimedia Commons, of course!) but the system now supports the territories as well:

Data sources:
[0] https://www.census.gov/geo/reference/codes/cou.html
[1] https://www.census.gov/geographies/reference-files/time-series/demo/metro-micro/delineation-files.html
[2] https://factfinder.census.gov/bkmk/table/1.0/en/PEP/2017/PEPANNRES
[3] https://www.huduser.gov/portal/datasets/fmr/fmr2018/FY18_4050_FMRs.xls
"The way of mathematics is to make stuff up and see what happens." --Vi Hart
January 27, 2014
Ooh! Hate mail!
Well, that's new. I just got my first piece of hate mail attacking me for daring to take a stand against the old boys' club.
A couple days ago, someone posted to Hacker News about a new command line tool for looking up and curating examples of how to run different programs---a useful-sounding idea---which they decided to call "bro". The software is described at and available from bropages.org.
The term "bro" is, to say the least, one that comes with a lot of baggage. I saw the HN post fairly early, and in the first hour or two there were a couple comments critical of this naming choice and a lot of comments raging defensively against these criticisms. I made a post that tried to articulate just why the name was problematic; if you read the HN post about this my post is right at the top, having been heavily upvoted by many members of the HN community.
It also got a lot of responses.
If you have the time, you can read them; if you're familiar with this kind of argument there's really not a whole lot of new ground there. But that brings us to today.
Two days after the shitstorm in that comment thread, someone tracked me down (not hard, since I put my email in my Hacker News profile, although he used a different email address than the one I posted there) and emailed me the following helpful advice:
You are a huge white knight on HN. Do you really think that shielding women from the horrors of products with the word 'bro' in the name will get you laid? Pathetic. Most women need less 'protecting' than a dork like you.
I'd never heard of him before, but casual internet stalking (i.e. typing his name in a search engine) seems to indicate that he's in sales at a UK telco company; not clear if he would self-identify as a "bro" but it doesn't seem out of the question. By the standards of hate mail this is pretty mild, of course---when it comes right down to it, more amusing than threatening---but it's a bit puzzling what would be the goal of an email like this, other than to try to intimidate someone into silence.
Well, you can see how well that worked.
"I work on the assumption that Facebook is working by default to make me look like an asshole to everyone who's connected to me, because I've seen it do it to others." --John Scalzi
October 20, 2013
Hey healthcare.gov, your username requirement is wonky
I can't figure out how to actually submit a bug report to healthcare.gov, so I'll just talk about it here as an example of poorly phrased instructions (and suboptimal user interface).
I decided tonight to go looking around healthcare.gov, the new Healthcare Marketplace with information about the new ACA (Obamacare) policies and, if you live in a state like Virginia, also the marketplace itself. The "outer" part of the website seemed fine for finding out what applies to you, what the different rules are, etc, but if you want to get a quote, you have to create an account. (Aside: I'm not really shopping for a new health plan---the one I get as a Commonwealth of Virginia employee isn't bad. But I'm curious about the ACA and trying to be an informed citizen, so I'd like to know what I could get if I were shopping for an individual plan.)
Once you've entered some preliminary information, you have to pick a username, and you're presented with this screen:
![['Create your username' form]](/images/healthcare-username.png)
on which it tells you that your username should be at least 6 and at most 74 (!) characters in length, and that it has to have "a lowercase or capital letter, a number, or one of these symbols _.@/-". Those symbols are apparently not "special characters", which the earlier instruction says not to enter; but more importantly, that's a bit of a strange instruction, right? Telling you that it has to have at least one of those four categories of characters?
And of course what they've written is not what they meant. As you can see from the screenshot, the username "asdfgh" is 6 characters long and contains a lowercase letter, but is not considered a valid username. Playing around a bit, the following are all considered invalid:
asdfghj _asdfghj _asdfghj2 /asdfghj Aasdfghj 123456 123456_
while these are considered valid:
2asdfghj asdfghj_ asdfghj/ Aasdfghj@ Aasdfghj2 123456a 123456a_ 12345a 12345A
So from what I can tell, the actual logic of this system (or at least, of the validator running on this form field) is that a username must:
- contain at least six characters (and no more than 74, but I didn't test that part)
- contain only numbers, letters, or one of the five given symbols
- start with a number or a letter
- contain at least one letter
- contain at least one non-letter
Of course, they probably didn't want to provide a bullet list of rules, and so someone tried to boil that down into a "simple" instruction which is, unfortunately, quite wrong. And not wrong in an acceptable direction---if they specified a rule that was more restrictive but accepted some usernames that violated it, that's not perfect but it's ok from a UI perspective. But people can follow this rule they've given and still get rejected.
Here's a fairly simple phrasing that would be (afaict) correct: "Choose a username that is 6-74 characters long. It must start with a letter or number, but cannot be all letters or all numbers. It may contain these symbols: _.@/-" This phrasing has the added benefit of being syntactically simpler (thus accessible to people with lower levels of reading comprehension---an important accessibility concern for government websites).
(Separately, they're in for a nightmare if they really mean that about it being case-sensitive. It won't be long before someone signs up with MyName and then tries to log in using myname (or vice versa), and then they're just angry at the system. Even worse if the system will grant the username MyName to one person and myname to another! Perhaps they just mean that it's case-preserving, i.e. that when they print your username out it will always preserve the case that you first typed it, but it will match case-insensitively, so that e.g. the person with MyName could type myname and still successfully log in. This is generally considered a UI best practice.)
I should point out, too, that for all the complaining above, there are actually a fair number of good UI choices on the website---not least that they do validate your input immediately and tell you if you've chosen an invalid username the moment you navigate away from that form field (by hitting tab or clicking away). So the possible scope for confusion is at least relatively limited... but they should still probably fix it. Even if only 1% of visitors got tripped up by this, with literally millions of visitors to the site we're talking about tens of thousands of people that could be better served.
"The next time you... find yourself talking to a linguist, ask them about their research (definitely!), but please don't ask them how many languages they speak. That would be like asking a wedding planner how many spouses they have." --DS Bingham
October 16, 2013
Bugs in ancient software: as88
In my Computer Organizations class, I use the venerable Tanenbaum textbook, now in its 6th edition, and this year I decided to go with the flow and use the assembler/simulator that he documents extensively (and tutorials at length) in an appendix to the book. The problem, of course, is that the code base is really old; it's written in K&R C, and copyrights and headers indicate that some of the files were last edited more than twenty years ago. But hey, it works! And it's not like the basics of assembly have changed all that much since then.
Except it doesn't quite work. The simulator and tracer run fine on the pre-assembled example files, but when I go to run the assembler, as88, even on an unmodified source file, it mostly runs (generating the appropriate extra files) and then segfaults right at the end. A little poking around shows that the crash occurs on line 36 of comm.c, where a call to fclose is failing. Some rummaging around the internet turns up a site in Italian that has discovered what appears to be the same problem, although their suggested solution doesn't work---the problem is not that input itself is NULL, but that something it references has already been closed.
Observing that this is cleanup at the end of the program, of resources that will automatically be cleaned up by the OS anyway, I thought about just commenting the line out. Buffer issues shouldn't be a problem, because this is an input buffer, so there shouldn't be anything buffered that needs to be written out (and we're done with the input, so we must be at EOF).
So, just commenting that line out seems to work. At some point I may find time to hack around further and see if I can figure out the real source of the problem, but if this duct tape I just applied continues to work....
"To put it bluntly, I believe the world is patriarchal because men are bigger and stronger than women, and can beat them up." --Roger Ebert
July 11, 2013
Disabling side-click in Ubuntu
Aggravatingly, the "side" click, what you get if you squeeze the sides of your mouse (if your mouse supports it) is by default mapped to "back" in several browsers. Since squeezing your mouse is what you accidentally and subconsciously do when you pick up the mouse, this is almost never what you actually want. Helpfully, Ubuntu has deeply hidden away any means of configuring this behaviour.
With assistance from the OSM help board I found this post about fixing it, for which I've given an archive link because the current version of the site has taken it away (although search engines still index it....) Anyway, here's the short version:
- Identify your mouse device. Type "xinput" in a terminal window. Mine is a "Mitsumi Electric Apple Optical USB Mouse".
- Identify the offending click events. Run "xev" and click with the various buttons of your mouse: probably left and right click are "button 1" and "button 3" respectively, 2 is probably a click on the scroll wheel, and actually scrolling the scroll wheel will be other buttons (mine is omnidirectional, so that's buttons 4-7). And the side click: in my case button 8.
- Go to the /usr/share/X11/xorg.conf.d directory.
- Use sudo and your favourite editor to create a file with the contents
Section "InputClass" Identifier "Side mouse button remap" MatchProduct "Mitsumi Electric Apple Optical USB Mouse" MatchDevicePath "/dev/input/event*" Option "ButtonMapping" "1 2 3 4 5 6 7 0 0 0 0 0" EndSection
except replace the product with your mouse device and in the ButtonMapping make sure you keep the buttons you use and zero out the correct side-click button for your device. - Restart X, or just reboot the machine.
Happy hacking!
"When we react out of fear, when we change our policy to make our country less open, the terrorists succeed---even if their attacks fail. But when we refuse to be terrorized, when we're indomitable in the face of terror, the terrorists fail---even if their attacks succeed." --Bruce Schneier
July 06, 2013
My holiday week
or, A geek at play
So there I was, working on my syllabi. One of my courses, new to Longwood but familiar to many of my Knox alumni, is a survey of various areas and, as such, doesn't have a single good textbook. In the past I'd posted a bunch of Wikipedia links as "reading", but was never quite satisfied with that solution; this time round I thought I'd try posting reading lists for several textbooks which students would be able to either borrow from other students (e.g. those who'd taken upper-level courses in AI or databases) or else read them in the lab (where I'd put older editions of my own).
I started building it as a plain old HTML page, and I wasn't very far in before it started feeling very clunky, with me having to re-type a lot of boilerplate stuff. Modifying things or adding details was getting more difficult. In short, it was dumb to do this by hand (and exceptionally so as a computer scientist). Designing simple databases to store this sort of thing is, in fact, one of the skills I teach in this very course! So I set aside the work at hand in order to develop the database.
It didn't take me long to work out an E-R diagram for the database I would need (and, to be honest, working on the first few pieces by hand was helpful for informing me on the structure of the data); I once again appreciated how useful the basic "draw a bubble diagram" tactic is at organising data. Having devised a data description that met my own approval, I translated it into a corresponding set of relational tables (another skill I teach in this course---how convenient!). Of course, I now needed to devise a front end, both to enter the data and, eventually, to convert it into a form to present it on the web to the students, that being the original goal. I could quickly whip out a program that would do so and function adequately, but I'd have to run it by hand to do updates and the output would, in any case, look a bit Web 1.0. It occurred to me that this was the perfect opportunity to learn one of the web front-end technologies that I've been meaning to pick up for years---it's nearly impossible to learn a new language or tech unless you have a project at hand to write in it, and here I had one that was useful, important, and yet fairly small. A perfect first project. So I set aside the work at hand in order to pick up Ruby on Rails.
Step one on that was to install Ruby, and the Rails extensions; I tried to do it through the package installer on our department's server, but ran into some conflicts---and the server software will be upgraded in the next few weeks so I didn't want to muck with it. I ran into similar problems on my own (office) desktop machine, though, and I thought it might be a version issue. So I set aside the work at hand in order to upgrade to Xubuntu 13.04 (from 12.04).
This was nontrivial, as with the latest version of the distribution, they no longer can fit the installer on a CD, and I had no DVD blanks. It occurred to me to try the over-the-net upgrade, which was suboptimal because I would have to go by way of the intermediate version (12.10), but I tried it anyway and it seemed to work... until after the computer rebooted it completely failed to respond to the keyboard or mouse. They were fine if I booted from an old boot CD, though, so I took that opportunity to, um, refresh my backups. Then, I had to go buy DVD blanks after all, and burn a copy of the 13.04 boot DVD (on a classroom machine, because mine was booted from a CD, meaning I couldn't use the drive to do anything else!), and install from that. It worked! Success!
Back to Rails---the web frontend I plan to learn so that I can build the database I'm working on so I can display my reading assignments for my course in the fall. It turns out that all that intermediate stuff didn't help, and the package install failed with exactly the same messages as before. (Note: the time was not wasted! I now have an upgraded system, and fresh data backups.) Further investigation showed that the preferred way of installing is not to go through the standard package systems but instead to use a Ruby-specific version manager. Which does seem generally superior but completely does not work with tcsh... so that required some working around. But in the end I got Ruby, and Rails, installed. And at the top of the Rails tutorial it suggested that the learning curve would be "steep" if you didn't learn Ruby itself first. So I set aside the work at hand in order to learn Ruby.
That wasn't very hard---I'd seen pieces of it before, and I was able to race through an intro guide because I already had some pretty strong cognitive hooks to hang things on: "oh, that's a lambda", "ah, default values for the hash table", and so on. I wrote an OO word frequency counter and lost count of the number of times I'd try something a bit complicated ("if I were designing the language it'd work like this...") and it Just Worked. So it went pretty fast. Success!
Back to Rails---the web frontend I plan to learn so that I can build the database I'm working on so I can display my reading assignments for my course in the fall. There's a fairly detailed tutorial that works through all the features of Rails you'll need, and it's well-organised to (mostly) hit details one at a time. It was particularly fun, because after the first few sections I was able to see the object of the next section and make my own attempt at implementation based on what I'd learned so far, thus identifying A) what I did already know, B) things I thought I was supposed to know but was still shaky on, and C) the New Thing that simply hadn't been covered yet and was about to be introduced (although in a couple cases I was able to make a well-educated guess about that part, too :). Basically, having a good model of metacognition helped me structure the process to learn it quickly and well. There were definitely a few places that had unclear prose (and a few outright typoes), though. There was a note on the page that they accepted fixes to the docs, and before I moved on I wanted to make some notes about what to update. So I set aside the work at hand in order to jot down some notes about documentation improvements.
That's a little cheeky, if you think about it, since I literally started learning Rails today but was planning to tell them how to fix their documentation. But, hey, open source! And I do have, um, a reserve of knowledge about related topics. :) The way they recommended submitting suggestions was simply to fork the project on github, make changes, and then submit a pull request---all of which I understand in principle but hadn't ever really gotten around to doing (in part because I haven't really done a lot with open source since before github days). I'd work on that later, after actually doing the database I'm theoretically still working on, here. As I was taking notes for changes, though, I realised I wouldn't be able to remember what I was talking about if I waited. Also, nothing like a simple set of small changes to A) jump back into open source work, and B) get around to learning github. So... you may see where this is going... I set aside the work at hand in order to figure out github.
Which, ok, was dead simple. (I kind of knew it would be.) First of all, they have the cleanest, simplest signup process I've seen in a long time. And right off the first page is a clear set of instructions on how to get started. I got git installed locally, followed instructions to get a local clone of the rails distribution, and picked the simplest of my noted doc edits to implement. Committed the result locally, pushed the change to github, and after a bit of hunting about for the button to initiate a pull request, did so. Mere minutes later the request got approved, so now I'm technically a contributor to the Rails project. :) Success!
Back to the rest of the documentation changes, which I still wanted to enter before building the database I'm working on so I can display my reading assignments for my course in the fall. Interestingly, I found that in the development version on github, a few of the typoes had been fixed, but quite a few problems hadn't been; and at least one issue was "fixed" incorrectly. So I put together a few commits of (most of) the rest of the issues, and made another pull request. Success!
And back to... actually working on the database, ultimately so I can display my reading assignments for my course in the fall. Well, tomorrow.
By one measure, I haven't gotten anything done this week. But by another, I've gotten a ton done. And by any measure, I've been immeasurably geeky this week. :)
"Freedom is kind of a hobby with me, and I have disposable income that I'll spend to find out how to get people more of it." --Penn Jillette
April 02, 2013
Java Scanner silent fail
I just made a discovery that will be of no interest to the non-technical folks out there.
If you use Java's builtin Scanner (as I've done hundreds of times) to read in a bunch of text, it turns out that if any of that text is not in the expected encoding, it just silently treats that as unreadable, which means hasNext() is false and it appears for all intents and purposes as if it's an end of file. Here's the catch: this happens as soon as the Scanner reads the bad character into its buffer, *not* when your cursor catches up to the bad character.
The way this manifests is that your data seems to be silently truncated for no apparent reason. If you look at the portion of the file where it stops, there appears to be nothing wrong there---and there isn't. The problem is somewhere in the next few hundred characters.
The workaround to this is, if you know what encoding your input uses (and you're sure there's no noise in it), you can specify it:
Scanner in = new Scanner (new File (filename), "ISO-8859-1");(similarly "UTF-8"). If you expect your data might be noisy and you don't have access to your data in advance to clean it up, I'm not sure that you can use a Scanner, although it's possible there's something involving rolling your own BufferedReader that you can do.
That took a stupid amount of time to track down, though. "What do you mean, you're at the end of the file? I can see more data RIGHT THERE."
"When judging the relative merits of programming languages, some still seem to equate "the ease of programming" with the ease of making undetected mistakes." --Edsger Dijkstra
March 04, 2013
Reason #73 why C++ is a terrible intro language
This particular one is so boneheaded I think I can explain it to you even if you have no particular programming background. Imagine that I have a set of instructions that goes something like this:
Write down your name.That part in bold---this obviously won't work, right? Once you run out of pennies, either you declare yourself unable to follow one of the instructions ("remove one of the pennies") next time round (which we call "crashing"), or else you cleverly let yourself go into penny-debt and keep track of negative pennies, in which case the debt keeps growing and you still never have more pennies than your name is long, and so you get stuck running these instructions forever (which we call "hanging").
Make a pile of pennies with as many pennies as there are letters in your name.
Keep doing this:
Write down an 'X'as long as the number of pennies is less than the number of letters in your name.
Remove one of the pennies
The following C++ is exactly precisely the same set of instructions as written above:***
string name;
cin >> name;
int pennies = name.length();
do
{
cout << 'X';
pennies = pennies - 1;
} while (pennies < name.length());
If a student writes that, it's by accident; they need to see that there's an error in the specification, because they really wanted that last condition to be pennies >= 0, that is, "as long as you haven't yet gone into penny-debt (negative numbers of pennies)". Or perhaps something else, but definitely not what was written. Because the algorithm, as written, is obviously wrong, and needs to crash or print waaaay too many Xs or whatever.
Except, in C++, it works.
The proximate reason for this has to do with implicit type promotion, and I won't explain it in detail except to note that if you try to compare a near-zero negative number to a number that is mandatorily non-negative (which we call an "unsigned" number), the negative number is silently converted into a very large positive number. No warnings, no errors. So what happens here is that you decrease the number of pennies from zero, so you have -1 pennies; and when it asks if that number is less than the number of words in the name, it does one of these silent conversions, so it's actually asking if the number 4,294,967,295 is less than the number of letters in the name. (Or maybe, if the number 18,446,744,073,709,551,615 is less than the number of letters in the name, or even on an older system if 65,535 is less than the number of letters in the name, but the principle's the same in any case.) Since this huge number is, well, huge, the instructions say, yup we're done here.
I don't know of a single other modern programming language (other than C itself) that has this same problem.*
So, okay, this is a teaching moment, right? We can learn to see in the documentation that name.length() would give us an unsigned number, right? Let's see: docs say it would give us a size_type. What's that? That's not one of the types we've seen before.
Right, so it turns out that in C++ you can make different names for the same type. This is helpful from a software engineering perspective, since you can give more things more meaningfully distinct names, and communicate with the other programmers on your project what the role of something is. It's a little rougher on the beginners, though. Is size_type the same thing as unsigned int?
Well, maybe. If you search on this question you find a lot of answers from some very self-righteous software engineers talking about how important it is not to assume anything about what type size_type represents, because, as it turns out, it may vary by what particular thing you're getting the length of. Strings, such as in the code above, could have one kind of size_type, while dictionaries or sets or tables might, in theory, have another.
Fine, fine, I just goddamn want to know if it's signed or unsigned. Maybe I can just look up its actual definition in our current installation! A teaching moment after all. Since I want to model for the student how to discover this information, I could start at either of the two libraries they could possibly know where to look: iostream, which is the only library they're explicitly telling the compiler to include, or string, which they might notice at the top of the documentation is the place where the string-related definitions are. But from either starting point, if I look at the included definitions, what I actually find is a series of instructions to include other definitions files, which each include others, and so on, with no index and no organisation that would be evident to an intro student.
So it's another teaching moment, I guess, where I teach them about the command-line tool grep, which lets them search a whole bunch of files at once. It turns up many places that use size_type and a few different places that define it. Aha! A definition! And it turns out that size_type is an alias for... size_t.
O. M. F. G.
It really just never ends. In this case, whereas size_type is specific to the particular data type being used (strings, dictionaries, etc), size_t is a more global definition that applies throughout the language. So it's a different kind of alias for one of the basic types of the language, this one baked into the language specification. As a result, I can actually find it on a documentation site, which tells me that it is, indeed, an unsigned integral type (but it's not actually specified which integral type, of course).
So, to recap: a student with a weak understanding of an algorithm writes it in a way that is unquestionably incorrect. However, it "works" anyway, due to a quirk of C++ that requires twenty minutes of explanations involving three different library files and several websites. (And that's not even counting the explanation, which I skipped above, of why a near-zero negative number would be rendered into a very large positive number, which has to do with a binary representation called "two's complement" that we've covered but didn't sink in for all of them.)
Are we done yet? Of course not. Because although we tracked down what our library uses for size_type, there is not a specification in the standard that it must be unsigned; which means that not only does this "work" when it's not "supposed" to, its behaviour may or may not vary between different systems. Fortunately, this semester I have everyone working on the department server, so at least I can test it in the same environment they do. But still, having to explain all of these quirks to students is a) difficult given their lack of experience, and b) taking up time that I'd rather spend teaching them how to think. It's one thing to tell an advanced software engineer that in order to understand what a program would do they need a deep multi-year understanding of the language itself, every layer of abstraction it uses, and full understanding of the hardware it's running on. It's borderline malpractice to force that on someone who has been programming for less than two months.
C++ is a terrible, terrible introductory programming language.
* Though to be fair, PHP and Javascript are also notorious for having some bizarre WTF** consequences of a few of their choices for language semantics, and have whole websites devoted to cataloguing them. I wouldn't recommend them as intro languages, either.
** Worse Than Failure
***Well, as close as one could reasonably get, anyway. There's a little bit of legerdemain around "writing down" being input vs output, but none of the adaptations affect the larger point.
BELATED UPDATE: A link to this post was posted to Reddit in September, where it accumulated a few comments in addition to the ones posted here directly. Hi, Reddit!
"Gaping at the color balance on the map is ridiculous because Republicans have proven beyond any doubt in the past 30 years that they are absolutely dominant in areas where no one lives." --Ed, ginandtacos.com
August 31, 2012
Attack! (Huh?)
So there I am browsing my daily comics, and for one of the sites, Firefox pops up this warning:
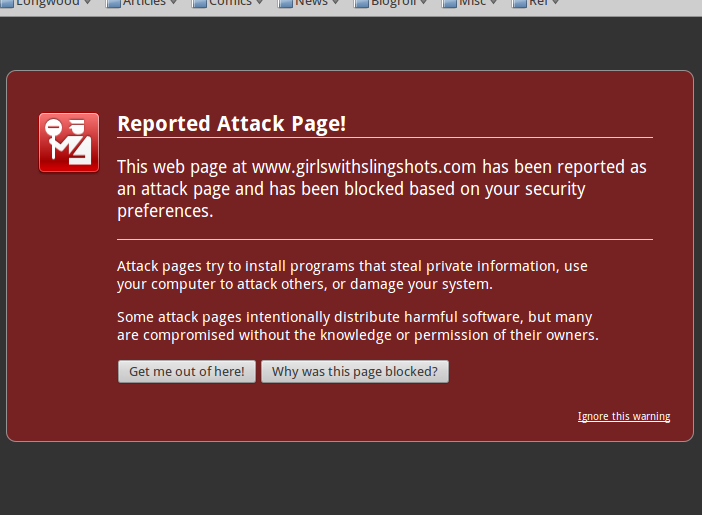
Whoa! The site must have gotten hacked, right? But I click on the "Why was this page blocked?" button, and got this response:

So... there are no attacks, no evidence of a hack, but you just decided to block browsing anyway? And this appears to be based on a Google list somewhere, which should be very scary for the site owner if this is more than just a Firefox bug: Google has made it very clear, repeatedly, that they do not give a single shit when their algorithms have some catastrophic effect on individual people or individual websites, and they make it exceedingly difficult to get a resolution (except for people who know somebody inside Google or can get a high-ranking post on Reddit or Hacker News, of course).
Perhaps I'm overreacting. Is there another explanation why Firefox would post big scary messages and block a site based on a Google list which, when queried, says there's no reason for alarm? I'm sure I'll think of it momentarily.
"A beautiful program with a single misplaced semicolon is like a sports car with one piston out of line. Both are dead machines, functionally indistinguishable from junk." --Kevin Carey
April 07, 2012
Long-lived printer queue
I finally just got around to hooking up my printer. It's been sitting in a box since I packed it up to move last Julynow that I again live very close to work, I'd just been printing anything I needed at work.
So I opened up the box and lifted out the printer. No cables there; I must have merged them in with the rest of my supply. So, dug out a standard power cable and a standard ethernet cable, and connected them. Then I pressed the power button, and it went through several minutes of self-testing.
When it was done, it said, "Paper out. Refill and press Start to continue." Ok, sure. Then I had to go track down my printer paper, but I found it, filled the printer, and pressed Start. I figured it was just going to print a test sheet or something.
What came out was a two-page programming problem that I had written for our Longwood programming contest back in mid-October. I stared at this for a moment. I have not thought about this problem in close to six months. I didn't even remember developing it on my home machine, although apparently I did (the files are there). So all I can think is that I absentmindedly hit Print six months ago, perhaps while trying to generate a PDF or something; and it sat in the queue since then. My computer has been rebooted several times in that interval, and assorted programs have been upgraded, but this lonely little print job has patiently waited for my printer to be reconnected, and sure enough, it was, and it jumped right to it and printed.
Now I kind of feel guilty recycling the paper. It went to such effort, you know?
"We have to stop looking at the government as 'them', and have to start reclaiming it as 'us'." --Rich Whitney
January 22, 2012
Gateway to the next level
(Originally posted as a comment on Hacker News.)
Haley Mlotek posted an article about her experience with Ladies Learning Code.
This is pretty great. Its first-order effects would be good enough: a successful class that turns people from mere users into content creators. Great!
But the second-order effects may be more important. Nearly anyone, when first introduced to computers, is "just" a user---they use the computer in the ways that are taught to them. Those of us that progress into general programmers generally had some transition phase where we were sort of "just users", typing something in or following instructions, but those things we typed in were our gateway to the next level. For me, it was typing in BASIC listings from magazines on the family Apple IIe in the mid-80s, and then figuring out that I could tweak them and make the programs do new things that weren't in the original article. For some of my students these days, it was typing in WoW macros and then learning to tweak their own.
A couple years ago, I had a student whose original entree into programming came via a web design class mostly involving HTML and largely done using a front-end app (Dreamweaver maybe?). But it was a start, and it inspired her to learn more about HTML and then eventually to take AP CS and major in it in college. I think her sex and her gender are only statistically relevant here---there most certainly are girls that play video games and will want to write macros, and there are boys that can will be well-served by an HTML-first curriculum. But she suspected, and I agree, that teaching people structured content creation will have long-term effects of increasing the ratio of females in all areas of CS.
But whether that speculation is accurate or not, let's not be dissing this person's experience because it's not programming-y enough. We don't need to be gatekeeping the secrets of the High Priesthood here; everyone needs to start somewhere. And whether Ms. Mlotek eventually goes on into "true" programming or not, she's more computer-empowered than before, so we should be happy for her, and if not her then others who go through this program, both male and female, will find their way into programming and other CS disciplines. And that is something we should all be happy about.
"Autotune... it's the audio equivalent to 'Snap to Grid'." --xpaulbettsx
January 20, 2012
Forget "where's my jetpack?", I want to know...
For Christmas, I got a wristwatch.
There's sort of a longer story there, but suffice it to say that I had been without a wristwatch for three or four years and had pretty thoroughly adapted to using my cellphone for the purpose. But I like a lot of old things and old-fashioned things, so I was grateful to wear a wristwatch again if only for the light affectation of it.
How quaint! He's wearing a watch! Do they even make those anymore?
Within a few days I was remembering to check it instead of going for the phone in my pocket. Within a few weeks (i.e. yesterday) I was annoyed when I accidentally left it at home, because I kept checking my blank wrist; and you know what? It's actually kind of annoying to have to fish your phone out of your pocket to check the time. Also, way harder to be subtle about it.
Today I followed that thought to its logical conclusion. If it's more convenient to carry the time on my wrist than to have to fish the phone from my pocket, wouldn't it be more convenient to carry the other functions of the phone on my wrist? I mean, people have been joking for years that if phones get any smaller we won't be able to see them (though smart phones arrested this trend somewhat), so the miniaturisation is totally on track to do this. Keypads would have been tricky to fit in there, but now everything's all touchpad-y so we might be ok there; and we would have needed both hands for an onscreen keyboard, maybe, except now that everybody's raving about Siri you can just hold your phone to your mouth and talk to it to tell it what to do.
There was a vogue a few years back lamenting the 1930s and 1950s visions of the future that still hadn't yet come to pass, often summed up with the pithy remark, "Where's my jetpack?" But now I'm thinking, hey, forget the jetpackwhere's my wristphone?
...it's coming. Soon.
"We may not always like what the First Amendment permits, but we've agreed as a nation that the short-term aggravation of personal offense is the tithe we pay for freedom." --Kathleen Parker
December 21, 2011
Therefore, install Linux
Early this past term I partitioned my MacBook hard drive so I could install Linux on (part of) it---at least in part because I was telling my students to do this, and I needed to make sure I knew what I was talking about. But also, the Mac system I'm running is aging and I really did not want to be giving more money to Apple.
At the time I installed Kubuntu (the KDE variant of Ubuntu). It was okay, but KDE has always felt sort of heavy to me. On my work desktop I'd installed straight-up Ubuntu, with Gnome, but that has been a bit of a fiasco the last year or so; I used to like Gnome okay, although almost as heavy as KDE, but Gnome 3 and Ubuntu's layer atop it (called Unity) are hard to use, harder to configure, and seem geared towards mobile tablets and pads as much as desktop and laptops. I actually went so far as to install fvwm on that machine, which was an improvement over Gnome/Unity (really!), and definitely very nostalgic, but it was not well integrated and ultimately was a decade or so out of date.
So one of my winter break projects was going to be to reinstall my laptop's Linux partition with other Linuxes to find one I was happier with. Having done some previous research, a likely desktop environment seemed to be Xfce (which may have been founded by former fvwm users, but in any case seemed to be the refuge of choice for several high-profile OSS folks who were fleeing Gnome/Unity). I was actually leaning towards Linux Mint Xfce edition, but was momentarily stymied by the distro ISO being DVD-targeted (my laptop only has a CD burner), so I went with Xubuntu instead, and so far I'm pretty happy with it.
Coming from decades of Mac use, and more recently two or three different Linux installations, I actually kind of feel like installing Xubuntu was like being led to the promised land. It really is the modern update of the power user's Unix/Linux environment that I came to love during college and grad school; I have access to all the crazy configuration options that Gnome and KDE have slowly been eroding or hiding away, but with a nice, fresh front end that doesn't make me feel like it's 1999. It has some of the very nice Mac-isms that I've long admired, like a dock (well, it's a "panel", and I had to do some configuration to make it match my Mac dock, but that's ok :), but it also has fixes for some of the things that Apple has broken (like good virtual desktops, which Spaces never managed to be). And I didn't even have to go diving into the text config files to turn on focus-follows-mouse---and I could turn on FFM without also activating autoraise.
There were just a few configuration issues that I had to go hunting for, which I'll document here for my own future reference as well as for anyone else installing Xubuntu (or, probably, any other Xfce-based Linux distro) on a Macbook. (For reference: currently it's Xubuntu 11.10, on a Macbook 4,1.):
- If you don't want tap-to-click, there seems to be no
place in the GUI configuration to turn it off. You need to run this command:
synclient MaxTapTime=0
- If you do want to be able to use the two-finger swipe motion to do horizontal as well as vertical scrolling, as you can on a Mac, you need to run this command:
synclient HorizTwoFingerScroll=1
(Vertical is on by default, but not horizontal.) - The default trackpad configuration in Xubuntu (Kubuntu too, as I recall) is way less sensitive than on the Mac side, with the effect that you have to use the pads of your fingers instead of the tip in order to use it. If that bothers you as much as it bothered me, you probably want to run this command:
synclient FingerLow=9 FingerHigh=13
- Finally, the MacBook's headphone jack is a dual analog/optical port, and when it's in optical mode it shines a red LED; and for some reason, this is turned on by default in Xubuntu (and apparently the other Ubuntus), with the effect that you have a red light shining out the side of your laptop. To turn this off,
amixer set IEC958 off
- Since each of these need to be run each time you start up, you probably want to automate this. Put all of them in a file that starts with the line
#!/bin/bash
and which is set to be executable (using chmod); then in the setting manager, go to Session and Startup > Application Autostart and add the file you just created, which will then be run every time you log in.
Happy Linuxing!
"The living people who call themselves Jedi may know with great certitude that Luke Skywalker never existed, but that doesn't keep them from being passionately devoted to what they believe are his ways, investing as much into their fandom as some folks invest in Christ. That they choose this as their religion has NOTHING TO DO with the literal reality of the story. Same goes with my belief in Christ." --Jonathan Prykop
November 01, 2011
BNCollege, your website is terrible
Barnes and Noble, I think it's fantastic that you're running the Longwood bookstore, don't get me wrong. And your general online presence is a reasonably decent experience. But your BNCollege.com interface, particularly the one you make me deal with as a faculty member, is terrible; you need to give your web programmers a talking-to about usability and actually knowing what their data looks like. Consider this a long-form bug report.
When we need to submit our book requests, we head on over to the bookstore's website, if we aren't sufficiently old-fashioned to entrust the job to our department secretary (who, as an aside, is pretty competent; in retrospect I should have been more old-fashioned in this instance and bypassed the web entirely). Once there, we're directed to a page with a multi-step process. If you personally haven't seen this page, it looks like this:
![[book request form]](/images/course-book.png)
Let's start at the top and work our way through. The first "step" is not only optional, but the usual case is to skip it, because as part of registering you made me give you my email. So this "step 1" is just sitting there wasting space. A venial sin, I suppose.
The next step (the first real step) requires me to select the term---my options being, at the moment, Fall 2011 and Spring 2012. A little late to be choosing books for this term, don't you think? More importantly, this field, and the department pulldown, reset every time so that I have to keep reselecting the same options over and over. Another venial sin, perhaps.
Here we come to the truly awful bits. Under step 3, you direct me to type in an ISBN in either its 10-digit (old) form or its 13-digit (new) form. Several of my books are more than a couple years old, so I type in their old-style ISBN. The response, after I click the "Search" button, is:
ISBN You entered is invalid. Please enter only numbers and '-' for ISBNIt's a little entertaining that this error message seems to permit dashes after the big NO DASHES warning, but the bigger problem is that the system is set up to reject close to 9% of all old-style ISBNs as invalid---the final "digit" of an ISBN is sometimes the letter X! As you, a book publisher, presumably know, and should probably convey to your web programmers.
It may not matter, though, because even for the books I had that didn't have an X in the ISBN, the 10-digit form was consistently not found in your database, even when (after I converted to 13-digit and retyped it) the book was in fact in your database. So maybe the answer is, you don't actually store the 10-digit ISBNs anymore, in which case you really need to update that entry form. (While you're fixing that, you should get rid of the "NO DASHES" restriction. It is trivial for the programmer to remove them after the fact, but letting the user type them in prevents an entire category of data entry error.)
In a couple cases I didn't have a current edition with me, so I didn't have an ISBN. No problem, because of the search-by-author box, right? Here's the thing: if you type in an author and title and click "search", the system takes you to another webpage where you have to type that same information in again. This is aggravating, and you are wasting my time, and the time of every faculty member who hasn't yet given up entirely on entering their book orders into your system this way.
Making it even worse, when I type in the author, title, and edition number on this other page---leaving the ISBN blank because I don't know it and the Publisher field blank because I think they switched publishers for the new edition and don't remember the new one---I am presented with a popup that says, and I quote,
Enter both author and title together.If your goal is to make your customers frustrated and angry, this is a superb message. It is less well-suited to informing your users that they need to provide publisher information. I'm not sure why you require publisher information anyway---since obviously some human has to interact with this information before it gets posted---but if you're going to not let me submit the form without it, tell me why.
Finally, at long last, you return me to the main book order form, in which you have now cleared all the information I entered in step 2. This happens no matter what when you enter your book selections, every time you enter your book selections. That's right: the order I'm actually supposed to do these steps is to fill in step 3 first, and only then fill in step 2. By this point, the entire process is making at least your art and math faculty customers think Escher must be involved someplace (the humanities profs are thinking of Kafka instead).
As it turns out, I am a computer scientist and I do understand that sometimes these bugs slip through, and it's important to be able to have bug reports if you hope to file a ticket and actually get the problem fixed. And I tried to do that. I looked for a bncollege.com bug report link, or a contact email for your web administrator, or any sort of place to submit this information. But then, in a final little zing, the "Feedback" link you provide links only to a many-page web survey that gives me no chance to actually tell you something. There is a "customer service" link, but that page has not one but three problems: first, the person it gives is a local manager, who will have no direct control over any part of the bncollege website. Second, the page gives a phone number but no email address for this person. And third, the web form that attempts to reinvent email, poorly, provides a tiny text box to write my message, clearly not adequate to the task of writing something like this (when the manager's just going to have to pass it along anyway).
So, naturally, I came over here to write it all up as an open letter. This has the disadvantage (for you) of making you look bad, because I'm laying out all the specific ways in which your interface is broken, and anyone can read it. It has the advantage (for me) that I can now send a link to the manager in that dinky little web form, asking for the URL to be passed along to someone who might be able to do something about it. Partly, I'm stubborn; partly, I'm documenting this for a nice case study I'll use next time I teach a web design or UI course; and partly I'm just being self-serving because I'd like for at least some piece of this to be fixed before the next time I'll have to deal with this piece-of-junk interface.
But, at least I'll post an update if you fix it.
Edit #1: Another little zing: by the time I typed my message into the dinky little customer support web form, "my logon session has expired." Sigh.
"At least four speakers at last week's Conservative Political Action Conference in Washington made Obama-teleprompter jokes while standing right in front of teleprompter screens, as though irony had never been invented." --Eric Zorn
September 23, 2011
Printing PDF/postscript booklets
So let's say you've got a PDF that you want to print at half-size. One option is to print it "2-up", which makes it so that if you put them in a full-size binder (and held the binder sideways) you'd read the pages in order, 1-2 on the first page, then flip that up and get page 3-4 and 5-6. I find this is great for academic papers and student work I need to grade.
But let's say you'd rather have it in a booklet form, so that you can take the stack from the printer, fold it in half, and have a ready-made booklet to read. This means that if the document were 8 pages long, on one side of a sheet you'd have pages 8-1, on its reverse 2-7, on the next page 6-3, and on its reverse 4-5. Fortunately, a lot of print drivers these days have a booklet option to automate figuring out this order, but if you didn't, you could rearrange the document into the order 8-1-2-7-6-3-4-5 and then print it 2-up as specified above.
But suppose, further, that you had a document that was long enough that a single booklet stack would be so thick that folding it in half would be impractical or even impossible. (This will happen between about 6 and 12 sheets of paper, depending on the thickness, representing a 24-48 page booklet.) What you can do then---and what bookbinders have been doing for centuries---is to print the book in "signatures" of 8 or 12 or 16 pages, folding these, and then binding them all together at the end. But you're not a bookbinder and you only want the one book. Is there a program that will automate this?
Well, probably, but I didn't find it and I got curious about whether I could do it from the command line. I can, and so you can, and I'm writing down the instructions here so that I don't forget them and as a how-to guide for anyone that stumbles across this page. You'll need a command line (Windows command prompt might do it, but certainly a Mac terminal or any Unix will do nicely), and you'll need to get psutils installed (its homepage is here but it's available through your favourite package manager as well).
First, if what you have is a PDF, convert it to PS. For my example I'll use the Longwood course catalogue:
pdftops UnderGradCatalog2011_12.pdf
Next, make sure that the file you will use has sufficient "gutters", or inside margins. Whether you're a proper bookbinder or just plan to use a couple metal binder clips, you need enough space without content on it to actually grip the page, on the left of the odd-numbered pages and on the right of the even-numbered ones. The PDF linked above does not, so first I'll use the general pstops reformatter. The odd pages I want to move to the right, in this case about 1.5 inches, and the even pages to the left the same amount, so I type
Strictly speaking this is telling pstops to move the even pages (those with page numbers = 0 (mod 2)) to the right and the odd pages (with page number = 1 (mod 2)) to the left, but that's because pstops is numbering from zero rather than one. The output of this is in temp1.ps and may require further tweaking to get it just so; don't skimp on that gutter margin.pstops '2:0(1.5in,0in),1(-1.5in,0in)' UnderGradCatalog2011_12.ps temp1.ps
Next, we want to shuffle the pages into a booklet order. Any multiple of 4 is technically a valid size for the signature; smaller and you'll be spending more time folding, larger and you'll have a harder time folding each one (and the signatures will be visible in the edge of the book). The size you give is the number of logical pages, and thus four times the number of sheets of paper per signature. I like powers of 2, so 32 sounded about right:
This program doesn't change the size or orientation of any page, just their order, and it should start with page 32, followed by page 1 (which the PS reader may list as page 31 and 0 due to pstops's numbering.)psbook -s32 temp1.ps temp2.ps
Finally, we want to actually 2-up the thing, as follows:
and then send that file (book.ps) to the printer! If you care to return it to PDF form for some reason, you can call ps2pdf on the file, but since this file will be useless in electronic form except to create more dead-tree copies, there doesn't seem to be much point in rendering it to PDF.psnup -n2 temp2.ps book.ps
And of course, the Unix Way would have you not cluttering the place up with your temp files, so you could just do
or evenpdftops UnderGradCatalog2011_12.pdf - | pstops '2:0(1.5in,0in),1(-1.5in,0in)' | psbook -s32 | psnup -n2 > book.ps
to send it straight to the printer.pdftops UnderGradCatalog2011_12.pdf - | pstops '2:0(1.5in,0in),1(-1.5in,0in)' | psbook -s32 | psnup -n2 | lp
"I have a coat older than Google. I have drill press older than the entire internet. I have books that predate the transistor. This is all new and we are just barely coming to terms with a giant sea change in every industry and cultural institution." --dan_the_welder
July 26, 2011
Gender balance in CS
(Adapted from a response to the HN thread "What happened to all the female developers?")
A frustratingly small number of people are aware of the 1984(ish) peak in females in the field. My mom taught computer programming (Fortran) in a Chicago high school from 1967 until 1984, and was actually kind of surprised when I first asked her about gender balance issues in the fieldthey just weren't an issue then, and her classes were always more or less balanced. But what they also were was everyone's very first exposure to a computer. Without exception, her students had never written any sort of program before, and they were recruited from good students in the math and physics classes, coming to programming with an open mind and no preconceptions. (A lot of them, girls and boys both, went into technical computer-related fields.)
The change, as has been noted elsewhere, surely has to do with the introduction of computers, but my hypothesis is that it wasn't just home PCs (not in the 80s) but classroom PCs that were the problem: in a lot of places, computers in the classroom were a fad and showed up with no training of the teachers, so they sat in the back or the side, mostly unused... unless one or two of the students pestered the teacher to play with the computer, and then used the manual and/or trial and error to figure it out. Guess which students were doing that more?
But that, I think, wouldn't be enough. The knowledge should equalise after one or maybe two terms of college CS, right? But I'm pretty sure the real problem was that professors inadvertently reinforced and magnified the difference between students who'd had previous computer experience (primarily boys) and students who hadn't (of both genders). It turns out that as a teacher, it's very, very easy to look around the classroom, see that X% of the students seem to be getting something, and decide to move on. (You can't wait for 100%, usually, so it's always a judgement call.) That's fine if it's something you've taught well and only the weak students are struggling, but what if it's something you absentmindedly glossed over? Half the class understands it, so you must have covered it, right? This is very insidious, and even being aware of it is not always enough to combat it; and if the divide of "has experience" vs "no experience" partially reflects a gender divide, that divide will only get reinforced.
"A popular implementation technique of hash tables is, rather than doubling (or halving) in size during resize, to just add or remove some constant number of buckets. And then still claim its O(1) cost for insert et al. It's a hash table, after all. At times like this, I understand why the zen masters tended to simply hit their students upside the head with a stick when they said something stupid." --Brian Hurt
May 30, 2011
Epson Scan won't work
I have an Epson WorkForce 615 all-in-one (scanner-printer) and was just getting around to setting up the scan part, and it just didn't work. It didn't even let you into the scanner program to configure it. There is a troubleshooting document that is completely useless because everything it says to do you have to be in the program already to do it.
Internet to the rescue: this two-year-old post detailed my exact problem and the exact solution (a separate config app that was silently installed and never mentioned in Epson's documentation. Thanks, Epson.)
"They're pretty crappy wood floors (they need a bit of work in the kitchen), which makes them only like 500 times better than carpet." --Benoit Hudson
December 22, 2010
Tau vs. pi: hyperspheres
I'd read a while back about Tau Day and the idea that τ=6.28... is a better mathematical constant than π=3.14..., for a variety of reasons. (Go read the Tau Manifesto and learn several of them if you haven't already.)
One of them was the idea that far from being a strength of π, the area formula A=πr2 is actually a weakness, because it camouflages the fact that there should naturally be a ½ in there, deriving from its integral relationship with the circumference formula. By contrast, C=τr and A=½τr2 display on their face the same relationship as, say, that between velocity and distance (under constant acceleration) or spring force and potential energy.
So anyway. I was thinking about the volumes of spheres, and I recalled that the formula was V=⁴/₃πr2; of course I knew that because I'd memorised it many years ago, not that it had any reason behind it:
| A=πr2 | V=⁴/₃πr3 |
| A=½τr2 | V=⅔τr3 |
| V2 (area) | =πr2 | =(1/2)τr2 |
| V3 (volume) | =(4/3)πr3 | =(2/3)τr3 |
| V4 | =(1/2!)π2r4 | =(1/2!∙4)τ2r4 |
| V5 | =(8/5∙3)π2r5 | =(2/5∙3)τ2r5 |
| V6 | =(1/3!)π3r6 | =(1/3!∙8)τ3r6 |
| V7 | =(16/7∙5∙3)π3r7 | =(2/7∙5∙3)τ3r7 |
| V8 | =(1/4!)π4r8 | =(1/4!∙16)τ4r8 |
But wait! What if we take that awkward extra power of 2 in the even-dimension formulas and distribute it over the factorial?
| V2 (area) | =(1/2)τr2 |
| V3 (volume) | =(2/3∙1)τr3 |
| V4 | =(1/4∙2)τ2r4 |
| V5 | =(2/5∙3∙1)τ2r5 |
| V6 | =(1/6∙4∙2)τ3r6 |
| V7 | =(2/7∙5∙3∙1)τ3r7 |
| V8 | =(1/8∙6∙4∙2)τ4r8 |
Check it out! Even if we don't have a deep understanding of what a double factorial is or how to compute the Γ function, we can clearly see the recurrence relation among the various dimensions, and the relationship between the even-numbered dimensions and the odd-numbered dimensions, and that they're much more closely related than might first appear from reading the Wikipedia article on n-spheres that I linked above.
So, chalk up one more success for the τists!
"When I go to get a new driver's license... or deal with the city inspector... or walk into a post office... I find public employees to be cheerful and competent and highly professional, and when I go for blood draws at Quest Diagnostics, a national for-profit chain of medical labs, I find myself in tiny, dingy offices run by low-wage immigrant health workers who speak incomprehensible English and are rud to customers and take forever to do a routine procedure." --Garrison Keillor
December 19, 2010
Time for an upgrade
It's been a loooong time since I've done a site upgrade. This place was already looking pretty dated a few years ago, and time has not treated it well. It had gotten to where I hesitated to post links because I knew I'd get the inevitable "Comic sans? Really?", among other snarky comments. And of course the web has long since moved away from coloured backgrounds, even light ones; pretty much anything other than white (or off-white) is hard to find among sharp-looking websites. But if I was changing things, I wanted to do more than just a trivial font change and a switch to a white background; other elements of the layout reflected an older web, and the last time I did a doc crawl on this stuff it was still the heady early days of CSS2, so probably more than ten years ago. You might be surprised to learn this, but a lot has changed in ten years.
So I'm working on a new design. A few minor changes will roll out early (where they show up directly in the HTML), but I want to wait to slide in the new CSS until I've tested it on multiple browsers. Soon, though.
"A human being should be able to change a diaper, plan an invasion, butcher a hog, conn a ship, design a building, write a sonnet, balance accounts, build a wall, set a bone, comfort the dying, take orders, give orders, cooperate, act alone, solve equations, analyze a new problem, pitch manure, program a computer, cook a tasty meal, fight efficiently, die gallantly. Specialization is for insects." --Robert Heinlein
December 07, 2010
Evidence from one coin flip
Earlier today, on Hacker News someone posted a link to Tom Moertel's blog post "On the evidence of a single coin toss", where he poses a question about probabilities: if he claims he had a perfectly-biased always-heads coin, and you toss it once and it comes up heads, should that sway your beliefs about the claim?
This was an excitingly interesting question on which I spent far too much time working out an answer, so to sort of justify the time I wrote up the answer and posted it on HN. I figured I should clean it up a little and post here. The tl;dr is that "it depends", first on your formalism (and whether you buy into Bayesian analysis), and second on how much you trust Tom in the first place.
There are at least three different lines of inquiry here:
- Hypothesis testing.
- If the [null] hypothesis is that p(heads) is 1, you can't prove this, only disprove it. So: "doesn't sway". Not very interesting, but there it is.
- Simple Bayesian.
- The probability of his claim given that it comes up heads, p(C|H), can be understood as[3] the prior of his claim, p(C), times p(H|C), divided by p(H). Well, p(H|C) is 1 (that is the claim), and p(H), if I fudge things a little bit, is about 1/2, so p(C|H) should be about double p(C)—assuming p(C) is very low to start with.[0][2]
- Complex Bayesian.
There's a hidden probability in the simple case, because p(C) is encompassing both my belief in coins generally and also my belief about Tom's truthtelling. So really I have p(C) "p that the claim is true" but also p(S) "p that Tom stated the claim to me". Thus also p(S|C) "p that if the claim were true, Tom would state this claim to me" and p(C|S) "p of the claim being true given that Tom stated it to me"; but also the highly relevant p(S|¬C) "p of that if the claim were NOT true, Tom would state this claim to me ANYWAY" and a few other variants. When you start doing Bayesian analysis with more than two variables you nearly always need to account for both p(A|B) and p(A|¬B) for at least some of the cases, even where you could sometimes fudge this in the simpler problems.
SO this brings us to a formulation of the original question as: what is the relationship between p(C|S,H) and p(C|S)? The former as
p(H|C,S)p(C,S)/(p(C,S,H) + p(¬C,S,H))
and thenp(H|C,S)p(C,S)/(p(H|C,S)p(C,S) + p(H|¬C,S)p(¬C,S))
and if I take p(H|C,S) as 1 (given) and p(H|¬C,S) as 1/2 (approximate), I'm left withp(C,S)/(p(C,S) + 0.5p(¬C,S))
For the prior quantity p(C|S), a similar set of rewrites gives mep(C,S)/(p(C,S) + p(¬C,S))
Now I'm in the home stretch, but I'm not done.Here we have to break down p(C,S) and p(¬C,S). For p(C,S) we can use p(C)p(S|C), which is "very small" times "near 1", assuming Tom would be really likely to state that claim if it were true (wouldn't you want to show off your magic coin?). The other one's more interesting. We rewrite p(¬C,S) as p(¬C)p(S|¬C), which is "near 1" times "is Tom just messing with me?".
Because a crucial part of this analysis, which is missing in the hypothesis-test version or in the simpler Bayesian model, but "obvious" to anyone who approaches it from a more intuitive standpoint, is that it matters a lot whether you think Tom might be lying in the first place, and whether he's the sort that would state a claim like this just to get a reaction or whatever. In the case where you basically trust Tom ("he wouldn't say that unless he at least thought it to be true") then the terms of p(C,S) + p(¬C,S) might be of comparable magnitude, and multiplying the second of them by 1/2 will have a noticeable effect. (Specifically, if p(C,S) and p(¬C,S) turned out to be exactly equal, then flipping once would make us about 4/3 as likely to believe the claim as before.) But if you think Tom likely to state a claim like this, even if false, just for effect (or any other reason), then p(C,S) + p(¬C,S) is hugely dominated by that second term, which would be many orders of magnitude larger than the first, and so multiplying that second term by 1/2 is still going to leave it orders of magnitude larger, and the overall probability—even with the extra evidence—remains negligible, with a very slight increase to the belief in Tom's claim.
[0] This clearly breaks if p(C) is higher than 1/2, because twice that is more than 1. If we assume that the prior p(H) is a distribution over coins, centred on the fair ones and with a long tail going out to near-certainty at both ends, the claim "this coin is an always-heads coin"[1] is removing a chunk of that distribution in the H direction, meaning that p(H|¬C) is actually slightly, very slightly, greater than 1/2. This is the "fudge" I refer to above that lets me put the p(H) as 1/2. Clearly if my prior p(C) is higher than "very small" this would be inconsistent with the prior p(H) I've described.
[1] I'm further assuming that "always" means "reallllllly close to always", because otherwise the claim is trivially false and the problem isn't very interesting.
[2] Note that this is not actually a "naive Bayesian" approach—that's a technical term that means something more complicated.
[3] This is what I meant about buying into the Bayesian approach. I'm going to continue the post under the assumption that Bayesian reasoning is valid (even if not what is traditionally called a "probability"), and I'm going to use the language and notation of probability to do it. If that doesn't sit well, imagine that I am quantifying something like belief or confidence rather than probability per se.
"How would Apple like it if when they discovered a serious bug in OS X, instead of releasing a software update immediately, they had to submit their code to an intermediary who sat on it for a month and then rejected it because it contained an icon they didn't like?" --Paul Graham
December 11, 2009
Good guys, bad guys
Remember when IBM were the bad guys?
Not so much that they were evil per se, but there was a time when IBM was the 800 lb. gorilla, throwing their weight around and making everyone negotiate with them or imitate them or, if they were particularly saucy, set themselves up as an underdog against them. IBM is International Business Machines, man! Who the hell is Apple?
Anyway, that state of affairs ended quite some time ago; it turns out that opening up your architecture for everyone to imitate, commodifying it, is fantastic at achieving the goal of getting everyone to adopt your architecture and less good for a bottom line based on producing high-quality instances of that architecture. Especially once the architecture has matured to a point where other than increased speed, the main effect of an upgrade is relatively minor tweaking that non-power-users won't much notice; it's hard to whip up a buying frenzy for minor tweaks. And so, after some time, the hardware battles ended, and IBM "won" but sort of receded into the background. These days I mostly know IBM for sponsoring programming contests, recruiting superb programmers, and developing large-scale "business solutions", which I sort of make fun of but honestly, it's a legitimate need and they seem to be doing a good job at it. So they're good guys now.
I'm beginning to wonder if 2009 Microsoft is in a transition similar to 1989 IBM. Certainly they're a dominant force that a lot of people are wary of, and supporters of Mac and Linux cheer for their respective underdogs; Microsoft has been hit with multiple lawsuits over the years about their monopolistic practices, some of which stuck and have caused them to change their ways.* Their Windows platform is matured in a way very dangerous to their Windows-centric business model: a vast number of their users would, if not absolutely forced to change, happily remain with Windows XP for decades. They certainly won't upgrade for the sake of upgrading if the "upgrade" isn't good, as we saw in the Vista debacle. I kind of hope they got Windows 7 right, because it may be the last major ("everybody switch") upgrade that they are able to pull off. The face of big bad Microsoft, Bill Gates, is fast becoming better known as a world-class philanthropist that tends to focus on education and global health.
And it's clear that Microsoft will not be the dominant force in the next era, as we graduate from OS/systems software to application platforms and the so-called "cloud".** Bing, which you may not have even heard of, is their search engine, but it'll never get the market share that other MS products have in the past. Zune, their similarly-obscure MP3 player, is hardly a bust but will likewise not be taking over the world. Even in the OS world, Apple has finally turned the corner and re-recruited two of their traditional markets from the 80s and early 90s, education and graphic design; and Linux variants such as Ubuntu have finally become viable options for people who aren't system administrators. Both are chipping away at Microsoft's market share, slowly but surely, and general developers are having to think seriously about making sure their stuff works for non-Windows users (if only by making it a web app).
Meanwhile, the new fronts in the computer wars are pointing to two likely candidates for the next "bad guy": Google and Apple.
Google has their famous mantra, "don't be evil", which may yet protect them, but boy howdy are they expanding into an entity you should be worried about. I do use Google for search, and after more than ten years, they're still great at that. I have in the past used Google maps, and will probably still do so from time to time, but their interface has gotten clunky and slow and I'm shopping for something better. But I haven't got a gmail account, I don't use Google docs, and I don't log in or accept cookies from Google so that they can track and coordinate what I'm searching for. GMail is particularly insidious because they can bounce email as "spam" with impunity, and if you or your ISP complain to them, their main suggestion is to just get a GMail account and use that instead. This has, of course, made me even more reluctant to get a GMail account, but maybe that's me. Just in the last few days, their CEO is on record as saying that if you wanted privacy for something, you shouldn't be doing itand that should raise the hackles of just about anyone.
Apple seems like a pretty unlikely candidate for Next Big Bad Guy, given that they've been underdogs in both of the last two rounds (first against IBM in the 70s and 80s, then against Microsoft in the 90s and 00s). The game-changer has been the fact that they were among the first to achieve success in the MP3 player market (with the iPod), the first to achieve real success in the per-track digital music market (with iTunes Music Store, which they successfully linked to the iPod), and the first to link cell-phones and PDAs with a (multi-)touch-based interface that everyone is now imitating (the iPhone, which they successfully linked to the iPod and iTMS). There's now much more of a my-way-or-the-highway attitude about them now that never was there before. And they're doing all the things that Microsoft did back in the 90s that we hated: muscling other companies out of their markets with anti-competitive practices, and taking good services provided by third-party addons and bundling with the OS an implementation that is buggy and crappy but that nevertheless drives the good implementations out of business (I'm still bitter about Spaces). Their handling of the App Store is already notorious in the developer community for how fickle and unreasonable they are in approving iPhone apps, how abusive they are of their third-party developers, and how much more they seem to care about control than quality.
It's not going to be easy to divest ourselves of either one. There are other music players, but the iPod's still a great design, and of course anyone that's bought much from the iTMS will have a bit of work in converting all their DRMed AAC files into something that other players can read. For the desktop machines, I've happily switched to Ubuntu at work, and as my iMac is still running Tiger (MacOS X 10.4, soon to be end-of-lifed) I'm contemplating Ubuntu-fying that as well; my future hardware purchases will almost certainly not be from Apple. Google is even harder, of course, although less hard for me than most (because, as I said, all I really use is search and mapping). For mapping, I may revert to Mapquest or Yahoo Maps, which were my servers of choice until Google Maps became draggable. For searching itself, I may try Microsoft's Bing despite completely making fun of it as recently as a couple months ago, but I've recently been put on to a lovely little number called DuckDuckGo that seems to have pretty good coverage and has some very nice UI upgrades over Google's search. The main thing there will be to retrain the muscle memory that puts me in the location bar typing "google whatever" and hitting Return before I've even actually thought about anything other than "Search".
Maybe I'm wrong. I'd like that; Google and Apple have been my heroes for a long time now, and it's too much fun calling Microsoft the Evil Empire to give that up easily. I think that age might be passing, but I'd be pleased to be wrong, at least about Google and Apple. Stay good, Google! Stay good, Apple!
*Sometimes the companies with the best practices in an area are those who have been burned in the past by having the worst practices. Nike, for instance, was one of the first big companies to be boycotted for running sweatshops in Asia, back before anyone knew or cared about "fair trade"; these days they're sometimes held up as a model for how big companies can outsource clothing manufacture in a basically responsible way.
**I really, really hate the term "cloud". I can't even say why. Bleah.
"Everyone at Knox is responsible for holding up the illusion that this campus is a microcosm of the real world. Obviously, nobody is going to care how or why feminists were denied a house in ten years, but if we don't fake it for a while, we'll never learn how to stand up for ourselves in the real world." --Deana Rutherford
November 04, 2009
How to treat a guest
Last weekend I attended the Cyclone Ballroom Classic (woo Knox) and I stayed at ISU's student union hotel. On check-in I was able to borrow (for free) an Ethernet cable that would work in the room, in case the wireless wasn't strong enough there (it was), and told there would be a (free) registration when I first connected. I believe it asked for my name, my phone number, and maybe an email address; quick to fill out and not terribly invasive. Then I got this screen:
![[Reboot now.]](/images/isu-reboot.png)
This was irritating. Why should I have to reboot? I started mentally cursing incompetence, but just in case I clicked the little question-mark help button. Which took me to this screen:
![[...or just renew your DHCP lease.]](/images/isu-dhcp.png)
And that fast, I've completely reversed my opinion of them. They're right! For the majority of users, rebooting is both simplest to explain and simplest to doand if they're not power users they're unlikely to have any long-running tasks that would be fouled up by a reboot. And, for the power users, ISU's tech folks have helpfully clarified that yes, a simple release-and-renew is all that's actually required, and if you know what that means, you can do that and not worry that some wonky setting somewhere will break anything. So they've effectively navigated the "easy for novices, effective for experts" divide that is sometimes so tricky. (And in fact I had internet all weekend with no troubles at all.)
Contrast that with this afternoon, when I was terribly embarrassed on behalf of my college: we had a guest speaker, invited by someone in the Spanish department, to give a talk (on queer identities in post-Franco Spain, which was a neat talk, by the way). Embedded in his presentation were a few YouTube links. What happened? Well, first of all, he got defaulted to an "open" wireless network that didn't actually connect to anything. Then he switched to the main Knox wireless network, but was presented with a login/password prompt, because we have no general guest setup. Robin Ragan, the host faculty member, rushed up and used hers, but this ordeal was not yet over: he was only placed on the provisional network, from which he could click a link to download and install the stupid malware that Knox forces its users to install on all their machines. (We're still in the middle of the talk, by the way. I wanted to crawl into my shoe I was so embarrassed.) So he did, but that wasn't enough, because once it downloaded and installed and ran, it informed him that his system wasn't up-to-date enough for it, so it would shunt him over to the quarantine network until he fixed the "problem". In the end, he had to manually type in the YouTube URLs onto the desktop machine in the classroom in order to play them. This, I'd say, is how not to treat a guest. Come to think of it, I should shoot him an email and warn him to make sure the malware gets deinstalledhe was a Mac user and the stuff is known to cause 100% CPU consumption on Snow Leopard. (We reported this a month ago. The Computer Center is "looking into it".)
"Both the Arabs and Israelis have unassailable moral arguments, and anyone who does not understand how this is true cannot understand the true nature of tragedy." --Nadav Safran
September 08, 2009
More linuxy stuff
Two new how-to items and an update:
Back in my Brown CS days I was converted to the One True Way of keyboards: Sun keyboards put keys you use more often closer to where your fingers already are, decreasing stress. What's not to like? But even Sun makes its keyboards to follow the PC standard these days, so you have to remap them. Easier on a Linux box than on other systems---just use xmodmap---but I had a strange behaviour whereby remapping the backspace key to be backslash (unshifted) or the pipe/vertical bar symbol (shifted) does remap both, but it remaps them both to the backslash. Mysterious. Googling on this, along with keywords like "Ubuntu" and "Jaunty", kept turning up ways to turn off a crazy behaviour whereby shift+backspace caused the X server to reset. But that's not what mine did! Even without the xmodmap, shift+backspace just did a simple backspace. Although, its xmodmap entry did read "BackSpace Terminate_Server"....
So here's what I think happened. The people that put together the default keyboard mapping packages had "helpfully" bound Shift+Backspace to terminate the server, which is terrible. The people that put together the keyboard drivers couldn't fix it the right way (by changing the key map), but were sick of the complaining, so they worked around it by making the keyboard driver remap Shift+Key22 to only send Key22, so that the next layer never even saw the shift key. What a mess. And it appears to even be upstream of Ubuntu; I saw a Debian machine exhibit the same rebinding behaviour.
Anyway, I finally found the fix in a post helpfully titled "Getting a pipe ("|") character with Shift-BackSpace key-combo" on the forums: you have to (as root) the file /usr/share/X11/xkb/symbols/pc and in the BKSP entry, change the type from CTRL+ALT to TWO_LEVEL. Then the xmodmap can proceed as expected.
Then today, I was trying to migrate my on-campus wiki over to the new machine. Since I hadn't played with it since I first followed the MediaWiki install instructions a year ago, I had forgotten a lot, and so I found a terse post on the subject to be very helpful... but not perfectly. What to do on the old server is correct:
mysqldump -u root -p wikidb > wikidb.sql tar -cvf wiki.tar wiki ;this is the wiki folder on document rootbut what to do on the new server is incomplete. Yes, you need to copy over and untar all the wiki files, but what about the database? I ran into two snags. First, the default MySQL install was not letting me in, giving me an "Access denied" error, either as root or myself, with any of my passwords. I still don't know what exactly cause it, but another post got me out of it, although even there it forgot to say to shut down the running mysqld first (e.g. with /etc/init.d/mysql stop). After the root password is reset, you can then restart the daemon and connect as described. What then? You want to connect to the wiki database and source the dump file you created.
$ mysql -u root -p wikidb Password: ****** > source wikidb.sqlNow everything's loaded, and there's one last thing (probably): you'll have to configure Apache or your local httpd to handle short URLs as described in the MediaWiki manual page on the subject. Whew!
Finally, an update on gizmod: it doesn't seem to do what I want. In order to capture keyboard shortcuts and translate them into other keyboard combos without also sending the original combo, you need to grab exclusive control of the device, which although they claim to support it doesn't seem to work correctly. Too bad.
"While many people who use the Web regularly feel pretty confident with it, we all know someone---someone close---who can never quite figure out whether or not the one-click purchase they just made on amazon.com is going to ship to the new house or the old one." --Robert Hoekman, Jr.
August 24, 2009
Migrating from Mac to Linux
I'm configuring an Ubuntu install on my new desktop machine at work, and as I figure out issues that were not easily findable on the web, I'll be posting them here, in hopes that someone else might benefit. Some of it will be most useful to Mac users trying to replicate Mac-ness; others to more general new-to- or returned-to-Linux geeks.
One random little tidbit that took me a while to figure out was how to configure the icons on my Launcher bar (the one that by default runs along the top of the screen but can be put on the side to resemble a Dock)---in particular, how to use my own custom ones. I'd discovered clker.com as a source of icons, and had a nice SVG mailbox that I wanted to use, which I copied to /usr/share/icons/gnome/scalable/, and when I browsed to it from the Launcher Properties dialog, it showed up in the browser, but after I selected it, the image was blank in the Launcher Properties dialog and some default image over in the Launcher. The solution? Make sure it's owned by root. Not sure why this matters, but after I chowned it to root, it worked just fine.
Another item: An awful lot of pages out there claim that there just isn't any good replacement for good old xv; certainly most of the ones that think there is point you either to a program that has no GUI at all, or to one that is a photo manager a la iPhoto, or else perhaps to the GIMP, which is way more power than I'm looking for when I fire up xv. However, one page, the "Grumpy Editor's guide to image viewers", itself already five years old, pointed me at a nice little package called gthumb, which is pretty darn close. There are a few minor issues, but it does: load up individual files (fast!), crop, resize, rotate multiples of 90°, and convert between the major raster formats. It also does some extremely basic color editing. I do wish that it had single-key shortcuts for things like "shrink by half", "grow by 10%", and "quit", but the newfound ability to resize to a precise pixel size, or select a crop on an 800% fatbits view, will make up for this.
And: I very much liked the Mac's screensaver that prowls through a directory of images and does a random pan-and-zoom on them, but I was having a hard time replicating this. First, one of the screensavers (slideshow) doesn't do the pan-and-zoom; but then I looked harder and found GLSlideshow, which does, although super-fast and with the whole image on the screen at once (with black bars alongside). Still couldn't configure it, though. At last I found a helpful blog post that gives the details. First, point it at your directory of pictures by creating a .xscreensaver file in your directory with the line "imageDirectory: /home/dblaheta/screensaver-pix" or whatever your directory is. Then, as root, edit the file /usr/share/applications/screensavers/glslideshow.desktop, modifying the line that says "Exec: glslideshow -root" by appending the additional options " -duration 15 -pan 15 -fade 5 -clip". This makes it more closely match the look of Mac's version (although you can further tweak these options---see the manpage for glslideshow).
To hyperconfigure my computer interactions, I've also discovered gizmod, which captures events (e.g. a keypress or mouse movement) and can translate these into other events; my initial motivation was to replicate the CursorMove functionality of fvwm, which I had been looking forward to in my return to Linux, in compiz which for various reasons I'm using instead. I hope it will also be useful in doing some per-application key remapping. I'm having some trouble configuring it, though....
More later as it develops.
"How about social conservatives make their argument without bringing God into it? By all means, let faith inform one's values, but let reason inform one's public arguments." --Kathleen Parker
March 12, 2009
Are you kidding me?
I just went to download a song from iTunes, to find yet another "the terms have changed" notice, as seems to happen every few months. You can't proceed without checking a little box that says, "I have read and agree to the iTunes Terms and Conditions." Except that the terms are just obscenely long, and of course they don't give you a diff, tell you what's changed; they know, as everyone knows, that nobody actually reads these. How could you? Can they possibly be enforceable under those conditions?
And they're not even trying. I tried to select the text so I could get a word count on it, and it wasn't selectable. So I clicked the "printable version" link, which opens up the page http://www.apple.com/legal/itunes/us/terms.html#SERVICE in a browser window. The "#SERVICE" part of that means it skips the top of the page (which is part of the text I'm supposed to have read). On the linked page, the top section is dated "Last updated: January 27, 2009", while in the corresponding section of the iTunes terms, it is "Last updated: February 23, 2009". So apparently, the two versions have been out of sync for about three weeks now, and nobody noticed. Unsurprising, and yet absurd.
Still, having grabbed the printable version (however out of date), I can get some stats on it. It is 23 pages in length, with the text alone clocking in at a whopping 110 kilobytes. And what are the contents of this dissertation I'm supposed to claim that I read in sufficient detail to agree to it? Well, it's divided into five main blocks that each have a somewhat different organisation but which collectively are parent to some 112 sectionsand some of those are further subdivided, as follows:
- Terms of sale:
- no helpful numbering, but with 29 labeled sections
- Terms of service:
- 24 numbered sections (several with lettered subsections, one of those with 16 roman-numeraled sub-sub-sections, and one of those with four double-lettered sub-sub-sub-sections)
- Gift certificates:
- 16 numbered sections
- App store terms and conditions:
- 34 numbered sections (several with lettered subsections, and one of those with roman-numeraled sub-sub-sections)
- EULA:
- 9 lettered sections
So let's play ball for a moment and suppose that I actually read this. You know what happens if you spend more than a couple minutes at this sisyphean task before clicking the checkbox and then clicking Continue? Yup, that's right.
![[Session Timeout: Your session has timed out. Please try this operation again from the beginning.]](/pix/itunes-session-timeout.png)
What makes this truly exquisite is that the left-pointing triangle in the upper-left there is greyed out. That means you can't even back up to the thing you were trying to download; you have to re-search for it from scratch. Nevermind the fact that my Apple ID still is visible in the upper right of the iTunes window, and when I do go back to the main iTMS home screen, the "Just For You" is in fact just for me; despite knowing precisely who I am and that I'm still the same person as before, they throw out my entire session for the grave crime of actually trying to spend some time reading the splatter of legalism that they vomit at my screen at fairly regular intervals.
I really need to find a different source for my online music. And my music players. And my computers. Apple has really been working very hard to turn away someone who's been a Mac fan for nearly two decades and an Apple user almost since birth. Smooth move, Apple.
"For more than 100 years this country has gradually extended rights, privileges and respect to more and more groups. To block a further extension you have to do better than cite tradition and the wounded feelings of those who already enjoy such status." --Eric Zorn
December 18, 2007
It arrived!

The picture to the right was taken by a really cool and newly-arrived device. More soon.
Relatedly, there is something special about this blog post.
"DST has only been around for 90 years; it's understandable that the software hasn't caught up yet." --Jim Wong
December 02, 2007
Random toys
I was getting caught up on the paper, and in last Thursday's had a column about a bunch of new DIY toys that range from the clever to the mind-blowingly cool.
The most "duh" one of them was something branded as "SquareOne", which bundles a tape measure together with a 90° square and a level, plus it has a writing surface and a place to clip a pencil if you're really lazy. I mean, of course you'd want to bundle a level and a tape measure! It makes perfect sense. And adding the square was really just a matter of changing the shape of the tape measure's enclosureamazing nobody'd thought of it before.
Grip-Tite is another one that I wouldn't really use, but sounds neat if I could only understand how it worked. The idea is that it somehow uses cams to make a socket wrench that grips a nut well enough that they can guarantee it'll never round the corners. Even looking at their diagrams, it seems like there'd have to be a spring or something that would be a major point of failure; but in any case, good on them for improving on what is essentially ancient technology!
By far the coolest thing in this article, though (I'm skipping a couple things), was the "SeeSnake" inspection camera. The reason it's cool is it fills a niche I'd never really even thought of but which immediately seems like it'd make a good addition to more or less every home. The idea is simple: put a very small camera at the end of a 3' cable and a display on the other end. Suddenly you don't have to pull out the VCR, DVD, Tivo, and receiver just to see what's wired to what; you don't have to smoosh your head on the floor so that your eye can see under the couch; and it becomes possible to e.g. look around corners in pipes and such. I think the best tools are the ones that seem the most obvious in retrospect, and this one pretty well takes that cake.
"I'll pause now so you can catch your breath after choking on the idea that the office of governor of Illinois is dignified and respectful. Three of its last seven former occupants have ended up in prison, after all, and the current governor is less popular than staph infections." --Eric Zorn
November 24, 2007
The Tivo-Airport-WEP saga
A few months ago, my dad upgraded the house wireless router to an Airport Express, and in the process set it to use WPA2 encryption. (The previous router was capable of some encryption, but we never used it.) Unfortunately, this prevented two laptops and the Tivo from using it. The laptops were a bit annoying, but the Tivo was not getting any program information, making it only marginally better than a VCR. My mom and sister just lived with it, but I talked my dad into backing the encryption off to WEP (which all the relevant devices could handle). This should have solved all our problems, but it did not. My laptop (an old Titanium powerbook running 10.3) now worked fine; his laptop and the Tivo seemed to think that the router was still demanding WPA.
I sort of spun my wheels on that for a little while, until Dad pointed out that what he had actually set it to was "WEP (Transitional Security Network)". That meant that my laptop, which didn't even know about anything more than WEP, worked fine, but the other devices, which knew about the existence of WPA, were having problems. Unfortunately, plain-old WEP was not an option; we thought it might be if we could change the router from "802.11n (b/g compatible)" to just plain old 802.11g (or b), but that wasn't an option. A tiny bit of googling turned up a page about exactly this problem that told us about the super-secret options: if you option-click that pull-down menu, other options (including 802.11b/g compatible) appear. And when you select that, the encryption option includes WEP 128 bit, i.e. "plain-old WEP". Hurray!
Except, that brought the other laptop online but not the Tivo. Despite the fact that that webpage was explicitly about Tivos and Airports Express. Hmm. The error message had at least changed; where it used to say "Wpa not supported"*, now the Tivo was letting us type in a password, and the problem was now that it was unable to find a DHCP server. Mysterious.
Some more googling turned up another page, also purportedly solving the problem of making Tivo work with an Airport Express, which says that deep in the bowels of the Tivo online documentation, they say that to work with an Apple router you have to enter the password in hex. It also gives the way to find out the hex version of your password, except that this post is three years old and its instructions do not apply to my dad's version of the Airport Admin utility.
Now, why would we need a password in hex? What does that even mean? Well, hex is just a convenient way to represent a raw numbertwo hex digits make up one eight-bit byteand of course the actual encryption algorithm uses raw numbers. In particular, the 128-bit WEP algorithm uses a 104-bit key (64-bit uses a 40-bit key), which is 26 hex digits (or 10 for the shorter one). That'd be hard for people to remember, so most manufacturers let you type an arbitrary alphanumeric password in and then convert that to a 26-digit hex number. As long as the conversion is always done the same way, the right password will translate into the right hex passkey. The problem is, different manufacturers used different algorithms, and since the modem and router are talking to each other in hex, the "right password" that you set up on (say) your Airport might not be the same "right password" you'd need on your Linksys modem!
Which is why you'll sometimes see advice about picking a password that's exactly 13 characters. The obvious way to convert a password into hex is to just take the ASCII value of each character8 bitsand write this down in hextwo digitsand so a 13-character password would give you a 26-digit hex key. Anyone that uses this obvious method for the 13-character passwords would be able to talk to each other. If there are less than 13 characters, there might be disagreement on how to pad it; if more, disagreement on how to truncate or hash it. But we had a 13-character password, and it still wasn't working.
Because something's funny about how Tivo's doing the password-key translation, I guess. Which means I need to find out how exactly Apple is converting its passwords into hex keys. Fortunately, googling for this information turned up a page at Apple that claims that all manufacturers use this "obvious" method if the password is exactly 13 characters. This is, evidently, false; but since it's Apple making the claim, I can assume that it is at least true of Apple. So I converted the damn password to hex by hand (using an ASCII table). Then I went to type it into the Tivo, was momentarily flummoxed when there didn't seem to be any way to actually enter the key in hex; it turns out there's a message in fine print at the bottom of the TV screen that says "Press INFO for hexadecimal". Do so, and it gives you a much smaller key entry table, though the digits from 0-9 you can just type into the remote's keypad directly. The software appeared to be set up to accept hex keys up to something like forty digits, which is odd, but I typed in the 26 I had, and from there on in everything worked perfectly.
Perfectly!
But because the info about this was so hard to track down, I figured I'd write it up. I know there's still a lot of series-2 Tivos out there, and as people upgrade their wireless routers this is bound to happen to someone else. (The disclaimer here is that by bumping the router down to WEP, your security isn't going to be as good as for WPA or WPA2, if that's a concern. Bumping it down to b/g compatible is also a slight concern, as you won't be getting the full 802.11n performance BUT if your network has any devices on it that run at 802.11g or 802.11b, having them on the network will downgrade the entire network to that slower standard, so making it actually "802.11b/g" instead of "802.11n (b/g compatible)" will not in practice make much of a difference if you've got older devices hanging around.)
*On this device. The Tivo itself can handle WPA, apparently, but the particular USB wireless modem that Tivo sold me couldn't.
"Phelps... believes in a god of hellfire, but he doesn't actually build the hellfire himselfhe's got enough faith to leave it to his god to do that. ...There's plenty of actual awfulness in the world; guys like Phelps are just poseurs, like trendy college Satanists, and responding to them as an actual threat just seems like it would do nothing but feed the delusion." --Jonathan Prykop
August 28, 2007
Ummm... bitte?
This is so gratuitous, and so Apple. I just filled out a survey about my recent AppleCare call, and after I clicked submit, I was presented with the following page:
![[Thank you in a dozen languages]](/images/apple-danke-small.png)
It is, in case you can't tell, a massive (and abused) HTML table with "Thanks" written in a dozen languages.* Of course, the AppleCare call was to their US line, the call was conducted in English, the followup survey was in English, and they certainly know that I'm an English speaker that lives in the US. SO VERY Apple.
*English, French, Spanish, Italian, two different Germans (or maybe "Bedankt" is also Dutch?), Russian, Japanese, I'm guessing Finnish, and three that are evidently related to each other but I don't know what they are.
"The breakthrough idea that seals my allegience to Christ is that goodness may pour out abundantly even from a chalice of wickedness, and so it is in forgiving the wicked that we cultivate what good is to be found, for great good and great evil often mingle inextricably in the same vessel." --Jonathan Prykop
August 25, 2007
Once again a Sun keyboard, at last!
Alllllmost. When I started out at Brown, the standard computer in use throughout the CS department was the Sun Ultra, with a good old-fashioned Sun keyboard. Some of the keys were in a slightly different location relative to the better-known PC layouts, and as I thought about it, I noticed that it was a lot better. The escape key was immediately to the left of the 1, which made it less of a stretchand as a vi user that used it all the time, that was a big improvement. The control key was immediately to the left of the A, and again, for users of anything other than a Mac, the Control key is likely to get considerably more use than the caps lock (which is what is in that location on virtually all Mac and PC keyboards, and even Sun has come over to the dark side on this one). And the backspace key was immediately above the enter key, again bringing a more commonly-used key closer than a less-used one (in this case the backslash).
{kind=link}
When we migrated to Linux, we got PC keyboards, which I promptly remapped to be like the old Sun keyboards, which were laid out better. Unfortunately, where the Suns had two keys (backquote and backslash), PC keyboards have a single, long backspace key. So the backquote key (and its shifted version, tilde) had to be dealt withI stuck them on shift-Tab and shift-Esc respectively (which actually put the tilde back where the keyboard has it marked). It wasn't my Sun keyboard, but it was a reasonable facsimile thereof.
I had a problem when I tried to do the same thing on my Mac, though. My remappings involved three different kinds of keysnormal, special, and modifierand no single remapping tool could deal with all three. On the Linux boxen I had just rebound the keys using xmodmap, a classic X tool, and this was able to handle most of it: but only for X apps, and it couldn't do caps lock. Indeed, caps lock was a special problem, because for a long time, Mac keyboards treated that key differently at the hardware level, with keypresses sending KeyDown and KeyUp events alternately, rather than both for each keypress. I tried a tool called uControl to remap caps lock, and I can't remember if it ever worked, but I know it eventually had problems with lapsing into locked control keys, so I had to abandon it.
Just a few weeks ago I was poking around in the Control Panels, and discovered that 10.4 introduced a new feature in the Keyboard panel: it lets me remap modifier keys at the OS level. So now I have my beloved ergonomic control key!
And that inspired me to go hunting for apps to remap the other keys. It'd been a long time and several OS upgrades since I'd last done so, and it was quite possible that what had been impossible was now possible. Just so! I found a little app called Ukelele (Unicode Keyboard Layout Editor), which can't handle modifiers but can handle both normal and special keys. Specifically, it lets me create a keylayout file, just like all the national keyboard layouts available in the International menu, which theoretically all apps should obey.
In practice, some apps, including a few of Apple's, trap for things like delete at a lower level than they're supposed to, and so the remapping isn't 100% successful. It's asymmetric, though: the keyboard's delete key, which I've remapped to backslash (and pipe), is sometimes trapped as delete. However, the keyboard's backslash key, which I've remapped to delete, is also caught as a delete. The backquote and tilde remapping seem to work everywhere. What that means is, in a behaving application, I get my remapping, and in a misbehaving app, I can't access backslash or pipe. Happily, I only ever type those when I'm coding, which I do inside X11, which behaves. And my better backspace key works everywhere afaict.
Are you a Sun keyboard aficionado who uses Macs? This file should work under any system version since 10.2; just put it inside ~/Library/Keyboard Layouts, and log out and log in again. You should then be able to access it (as "SunLike US") from the Input Menu tab of the International control panel (you'll want to also select the "Use one input source for all documents" radio button).
In my investigating I also ran across an interface for rebinding Control-key combinations to input field actions that are supposed to be universal across all Mac apps, just by making a DefaultKeyBinding.dict fileso I might actually be able to get even more Unixy functionality up and running soon. Woo!
"What makes such briefings disappointing is partly that they often run on far too long and are full of words like 'dread' and 'imbue', and either take themselves very seriously or, which is worse, don't." --Graham Nelson
August 17, 2007
Initial reviews of 4th-gen iMac
![[a new iMac]](/images/imac.jpg) And now I'm also the owner of a brand-spanking-new iMac of the new generation just announced and released last week. The monitor has a 24" diagonal, which is absolutely immense. The computer arrived yesterday, and I spent four hours moving stuff over from my desktop machine at work, so that when I first logged in it had successfully migrated all my old settings without a lot of tedious setup.
And now I'm also the owner of a brand-spanking-new iMac of the new generation just announced and released last week. The monitor has a 24" diagonal, which is absolutely immense. The computer arrived yesterday, and I spent four hours moving stuff over from my desktop machine at work, so that when I first logged in it had successfully migrated all my old settings without a lot of tedious setup.
Actually, you know what? I'm not even sure how it did that. Because among the files that were transferred were a whole bunch of Fink-installed files, which are not in Mac's .app format and were compiled for the old system, which was a PowerPC G5. This one is a new Intel-based Mac. And yet, they work. Now, I know that Rosetta is supposed to let me run old PPC apps more or less seamlessly, but I didn't think that the OS support for legacy code ran quite so deep.
It looks pretty slick; Apple's aesthetic sense triumphs again. It's also noticeably faster at a lot of things. But I have mixed or negative feelings about most of the things that work differently:
- The keyboard. Honestly, this change is sexier than the change on the main box; it is wafer-thin and somewhat lighter than the previous model, though not so light that it would lack heft. The keys have a rather different feel when it comes to touch-typing, but I'm already adapting to that. My complaint as regards the keyboard has to do with the function key row. Now, in Jobs's presentation he made a big deal about things like brightness controls and sound being right there in the function key row, as if this were a new thing. But I already had thosebrightness on my laptop, and volume on both the laptop and the desktop model. But, and this is completely obnoxious, the volume controls are attached to different keys on all three. Apple needs to MAKE UP THEIR GOD DAMN MIND about where they're going to put these keys, and stop moving everything around. The keys for things like Dashboard and Exposé are also, I think, different from where they used to be by default. What makes this all doubly problematic is that afaict the "special functions" (brightness, dashboard, expose, rewind/pause/forward, and volume) are active on some sort of hardware level, with a "fn" key you can hold down to make the F-keys be simple F-keys again. Which, if true, would mean that I can't even rebind them to match what I'm used to. I'm also not sure the physical key caps can be removed and rearranged as they could on earlier models.
- The monitor. It's very big. That's kind of cool, although I'm finding I need to sit a little further away from it not to be overwhelmed. The problem is, it's really bright. There's a brightness button, but it just spans the range from "painfully bright" to "blindingly bright""dim" is simply not an option. I haven't even used the computer that much yet and I'm getting eyestrain from it. This is, as you might imagine, a problem.
- iPhoto. In the Jobs presentation, I think one of the more exciting things was all the really nice changes they made to iPhoto. The problem is, every time I try to load it up, it tells me I need to upgrade my library before I can use any of my existing photos, but then it utterly hangs less than a minute into this process (which claims it should take about fifteen). Lame.
- Desktops. In particular, VirtualDesktop, a piece of software I've relied on for many years to manage limited screen real estate. Unfortunately, for some reason, it doesn't appear to work on the new machine. It loads, and its dialogs and preferences seem ok, but it doesn't actually do any of its desktopping. It's awful; even though my onscreen pixel count has gone way up, if I'm not able to keep at least a few virtual extra screens out there, I've lost real estate overall. Lame.
I have a support email out on the last problem and will be calling Apple tomorrow or Monday about the iPhoto thing. The others, though, seem a bit more intrinsic.
"Looking back at the early microcomputers is like looking at the fossils in ancient shale, before evolution took out three quarters of the species, some of them weirder than anything living today." --Graham Nelson
August 14, 2007
Mmm, subversive
I now own one of these:

But that's not the interesting thing. What's interesting is how delightfully subversive someone at Apple is. On the packaging for their flagship music-and-video device, Apple has placed a picture of a pirate. Who gets away with everything. And is grinning at the camera. And this has been the case for quite some timesomeone must have noticed, so presumably they don't care.
Piracy and iPods: two great tastes that taste great together!
"My biggest concern in the 107th Congress is that Bill Clinton will be with my wife in the Senate spouses club." --Sen. Gordon Smith, R-OR
August 08, 2007
The spam arms race
You might have noticed that there's been a recent increase in spam getting through. I was a little worried, but a scan of the logs seemed to indicate that these spams were just as random as all the squillions that didn't get through. Then I noticed: all of them had gotten the "future/past" question. And it turns out that those were judged correct if the correct answer appeared anywhere in the responsewhich "past" in particular did, since the bots tend to just enter one of their spammy posts into that field.
So there's a new version of BotBlock up, the first in two and a half years, that fixes that. Dunno if anyone else uses it, but it's still the best tool I've seen in the escalating arms race on spam (though I do know it's a little buggy and occasionally rejects correct answers... sorry about that. Just try again!).
"Computer science is no more about computers than astronomy is about telescopes." --Edsger W. Dijkstra
May 07, 2007
λ
I'd just like to note with amusement that my lecture notes on the lambda calculus are still in the front page of Google hits for "lambda calculus". I finally got around to keeping a local copy, but it's the one on Brown's servers that will stay in the Google hit cache. :)
"The main issue appears to be that Gonzalez got caught lying to Congress, and Rove appears to have blood in the water. Again. So the Democrats are using the subpoena power and the Bush administration has no idea how to react to a Congress that doesn't just go "okah" when they tell a bald-faced lie." --Mike McCool
May 01, 2007
Even geekier dreams
Flunk Day is really at the top of everyone's consciousness right now, and I've probably had five conversations about it in the last day. As a result, I had the dream again, which officially makes it even geekier: it's now a recurring recursing dream.
"A teacher has to walk a narrow path: you want to encourage kids to come up with things on their own, but you can't simply applaud everything they produce. You have to be a good audience: appreciative, but not too easily impressed. And that's a lot of work. You have to have a good enough grasp of kids' capacities at different ages to know when to be surprised." --Paul Graham
April 30, 2007
Geek dreams
I had the weirdest recursing dream last night. I think it went at least three levels deep, all occurred in the hour before my alarm was scheduled to go off, and had to do with (at various levels) it being Flunk Day, me erroneously thinking it was Flunk Day, me oversleeping my alarm, me turning off my alarm because it was Flunk Day or I thought it was, waking up and being upset I missed Martin's class again, waking up and being relieved it was Flunk Day, etc, etc.
Today was not Flunk Day.
"It's too bad you can't roll around naked in an online bank statement." --Jonathan Prykop
January 11, 2007
Speaking of "nerd credentials"...
Was I the only one who heard Steven Colbert dissing iPhone vis-a-vis nerd credentials, and thought, "FORTRAN 77? That didn't have recursive procedures!"
Thought not.
"Grad school applications are even hard for non-smokers." --Arun Bhalla
January 07, 2007
Kids, don't try this at home
I just got home and pressed a key to wake up my laptop's monitor, and was greeted with the plaid screen of death"ah, that was to be expected," I thought. Figuring it couldn't hurt and might help, I banged it a couple times (to no effect), and then dropped the computer from a height of about two inches. It was instantly perfect.
Still gonna buy a new one next week, though.
"I don't know, Dave, you don't sound much like an Asian whore." --Greg Seidman
Verdict: enh
Well, Python's okay. There are definitely some neat things about it, like list comprehensions (which subsume map and filter into a single, more generic form that incidentally makes lambda a lot less necessary, though that's still present too). Making % a sort of universal sprintf operator was a cute idea, and allowing while to have an else just like if can, well, it seems counterintuitive at first, but can make for some nice, elegant algorithm specifications.
Some things are just a lot more clunky, though. (Than perl, which is my main point of comparisonthey occupy roughly the same ecological niche.) For instance, all functions need to be declared prior to use, afaict. That makes it harder for me to organise my files the way I want to. I kept running into problems with things being passed by value when I wanted reference, or vice versa, and the way it handles global/local namespaces is just bizarre. (You can read from variables declared in an outer scope, but if you try to assign to them, a new local variable with that name is silently createdand disappears at the end of the current scope, of course. Eeuuchh.)
The worst thing, though, was the ubiquity of the exception system. As in Java, any time anything goes wrong, an exception is raised, although even more soiteration, for instance, works by just calling next() until the StopIteration exception is raised. That's just an abuse of the word "exception". But even where the term "exception" is legitimate, e.g. with an IOError, a system that is merely mildly annoying in Java becomes unforgivably cumbersome in a language that is intended for (or at least used a lot in) quick scripting. In Perl, to open a file and quit gracefully if anything goes wrong, you write
open FI, "<", $filename or die "Bad file $filename, aborting";But in Python, you write
try:
fi = open (filename, 'r')
except IOError:
print "Bad file %s, aborting" % filename
sys.exit(1)
I'm going to go out on a limb and guess that a lot more Python scripts just skip the error checking. Of course, the consequences are milder: rather than mysterious oddness you just bother the user with several lines of confusing tech-gook (from an uncaught exception). But a well-written script should have the checking either way, and in the Perl script it is not clunky and even aids readability if done right, while in the equivalent Python script it chews up five times as much space and interrupts the flow of the code.
So my overall opinion is totally lukewarm. I suppose I'll write a few more programs in it just to get a better feel... but I'm not really in any rush to do it.
"Toss out words like "sexual behavior of teenagers," "virginity" and "highly effective" and the parents of adolescents claw their way to newsstand and keyboard in a panicky search for enlightenment, looking, always, for relief from the kind of angst they heaped on their own elders just long enough ago not to remember." --Salon
January 06, 2007
Restful geeking
By the end of the day yesterday, I was feeling pretty strung out; all that sleep deprivation was catching up, and I had no pressing commitments to keep me going. When I sat falling asleep in front of my laptop, I decided to head on up to bed. That was around 8:00.
I got up around 2:30 this afternoon (after being woken by my alarm at 8 and shutting it off again) and decided to commit the day to learning Python. I've been meaning to for a long time, and another Knox person had requested that I (or somebody) write a program for himit seemed like the perfect excuse. As I sat down, though, it dawned on me that this is really the first new language I've learned since I learned C++ in 1997 and Java, Scheme, and ML in 1998. (Unless you count SQL, but I'm not sure I really "know" that one.) Those early years of grad school were busy ones! For all my preaching about how "good for you" it is to be multilingual and always be learning new languages, I haven't exactly practiced it very well.
Anyway, so now I'm learning Python. I'll let you know how it goes. I may eventually get used to the whitespace thing; that's just syntax, after all, and some of the semantic details of the language I'm finding quite nifty.
This is also as good a time as any to report that my laptop, faithful companion for more than five years, is about to be retired. In the last couple of days, it has developed a screen issue whereby sometimes, randomly, the display will start flickering from the bottomsometimes just once or twice, sometimes making the whole thing unreadable. Sometimes leaving it be made the problem go away; sometimes even pressure to the wrist rests worked better. This, together with the recently-broken power brick and the overall age of the systemand most importantly, my intent to get a new iMac anywayhas just accelerated my plans to get a new computer, and retire this one. As of my December paycheck, I'm now in surplus funds again, and even with banking for a rebuild of my back porch steps (which are falling apart), I'll be able to afford a modest computer by the time my next credit card statement arrives. (Actually, without banking for the porch, I'd be able to afford the computer now.) So at this point I'm just going to wait a week for the MacWorld Expo announcements and concomitant price drop, and then I'll be placing an order.
"I exist simultaneously in every internet conversation across all spacetime. I've been participating for years in debates that haven't even started yet." --Jonathan Prykop
June 29, 2006
Memory management
God dammit I &^%$ hate having to do my own memory management. How much time is wasted in software development around the world just trying to track down that leaked pointer or that null pointer dereference? AUGHGHHHH.
"Something's been sticking in my craw. No surprise there; I was born with an unusually narrow craw." --Stephen Colbert
June 13, 2006
So stupid!
Night before I fly off to SC to grade AP exams, and what do I do? Stay up all night watching the other six episodes of Firefly.
...but they were really, really good.
"It's like Jesus ascended into heaven, and it was all downhill from there." --Jonathan Prykop
June 09, 2006
Diverse pursuits
With the extra time afforded me by the end of the term, in the last few days I've dusted off and posted two complete side-pursuits from my academic past.
The first is a short essay on the history of the Principle of Indifference. This is from late in grad school, and actually appears as an appendix of my thesis. Basically, I was writing one of my thesis chapters, and referred to the principle, so I figured I'd cite it. The problem was, all the books I read that talked about it either omitted the citation entirely or made some vague handwavy reference to Laplacebut without an actual cite. So during a time that I really should have been hard at work on real CS stuff, I was exploring Brown's sci li, pulling 300-year-old books out of the stacks and reading them, in four languages. It was great fun, and this essay was the result. (It's short, and an easy read!)
The second diverse pursuit* is even older: it dates back to my sophomore year of college. In those heady days, a bunch of us spent a lot of time putting together paper models of assorted geometric objects, and I did some calculations for some torus nets, which I assembled and then forgot about. Well, someone remembered (the whole story is over on that page), and recently I went back and revamped the original nets and wrote up an explanation of how the calculations went. The math isn't actually all that difficult, although envisioning intersecting shapes in three dimensions can always be a bit dicey. :)
*Can a single pursuit be diverse? Or are diverse pursuits like stoplight peppers, in that it describes a set of distinct and countable elements, but only in the plural?
"The adolescents and the young... must be liberated from the widespread prejudice that Christianity, with its commandments and its prohibitions, places too many obstacles to the joy of love." --Pope Benedict XVI
Going even wronger
Following up on my rant from last night: Wired has an article about how the government is so scared of drugs and terrah and we are so scared of any risk to THE CHILLLDRUN, however small, that home chemistry sets, and amateur chemistry as a whole, is basically impossible at this point. This archetypal way to get kids interested in science, gone. One company tried to put together a new release of a Mr. Wizard kit, but discovered that more than half the chemicals were illegal or would expose the company to too much liability. Another company got raided by the feds for the horrible crime of selling chemical reagents.
It's really fucking depressing, is what it is.
"I disagree: I think it's a debate about whether you think gay people are part of the human condition, or just a random fetish." --Jon Stewart
The future held such promise
Where the hell did we go so wrong?
Twenty-five years ago, I grew up watching a bunch of different kid's TV shows. What was on then? Sesame Street. Pinwheel. The Electric Company (in reruns). Mister Rogers. Today's Special. 3-2-1 Contact. Most of them on Channel 11, Chicago's PBS station, a few on Nickelodeon.
You know what they weren't? Toy commercials. You could get a couple of Sesame Street-related things, but nothing like today; 3-2-1 Contact had an affiliated magazine that was itself pretty educational.
You know what else they weren't? Completely inane. In the past few years, I have had the misfortune to see a few pieces of children's programming, and it's like aliens invaded between the early 1980s and now. Adults watch "modern" educational programming and feel their brains slowly melting out. But, find an Electric Company clip on YouTube and, whether you get a nostalgia burst or no (I don't, actually; although I recognise the theme song I don't remember any of the characters or scenes from that show) you get the feeling that you could watch whole episodes of it.
And the most important thing that they weren't? Patronising. Every one of them is clearly children's programming, and yet they treated their audiences like people, and they educated them. They didn't just socialise them, which is what the newer shows seem to be doing, afaict. When kids were present in the shows, the adults (and puppets, and animal sidekicks) would have conversations with them. (This probably contributes to the non-inanity, come to think of it.) They pitched it to their target audience, but you don't get the feeling that they held back things that might have been too hard; their job was to get kids excited about knowledge and reading and learning and discovery.
Watch these clips: parts one, two, three, and four of the very first episode of 3-2-1 Contact, broadcast in 1980. There's stuff in there that I didn't learn until grad school; most of you would learn at least a few things from the episode. And although the technology is aged, I bet there would be at least a few things in there to make you go, "oh, cool!". But for all that, it's still clearly a kid's show from start to finish, nothing in there is truly out of reach for, say, a precocious eight-year-old, with most of it probably working just fine for a 6yo or younger.
So what happened? To my knowledge, there's nothing like this anymore. Any of it. Sesame Street is still on, but it's a very different sort of show than it used to be, with selfish, bratty Elmo promoted as its flagship, a paragon of childly virtue (available in six tickle-me variants for just $30 each!). Mister Rogers and some others are still in reruns in some places. But what have they been replaced with? Patronising, mind-numbing, inane, feature-length toy commercials.
The Electric Company put it on the line, right in the intro: "We're gonna bring you the power." An all-star cast on your TV day after day helping you learn to readno matter what your race, gender, or classto give you the power to do whatever you wanted to do, be whatever you wanted to be. The others, even without the famous people in the cast, aren't something just to keep your kid distracted and give you a break. They're the real deal, funded by groups like the National Science Foundation and the US Department of Education and of course the Corporation for Public Broadcasting to make kids excited about learning.
What the hell happened?
"The Ten Commandments are not a series of 'No', but a big 'Yes' to love and to life." --Pope Benedict XVI
May 25, 2006
Mixed blessing?
Because my sister is really really cool, I'm now the proud owner of the Firefly DVDs. Because her timing is poor I now can't watch them until sometime next week at least. Until then they will sit beside my TV. Taunting me. Argh.
"Put people in direct control of the stuff around them and they will, more or less, on average, be happier. It explains why some people like stick shifts, it explains why lethargic user interfaces make you frustrated and depressed, and it explains why people get so goddamn mad when Sony decides to install viruses on their computers just because they tried to listen to a CD." --Joel Spolsky
May 22, 2006
Citation quest
In my last post I dropped in the phrase "one non sequitur after catfish" because, well, it's a great turn of phrase, managing to illustrate the idea within the sentence in a sort of higher-level onomatopoeia. I had thought that the phrase, catfish and all, was a moderately well-known way of accomplishing this illustration (hence decreasing their mutual information entropy and thus actually making it less illustrative, but anyway).
It turns out that googling for the phrase turns up only that post (as observed by Lee, who also pointed that damn, but google spiders this blog frequently). So where could I have gotten this from? I certainly didn't come up with it myself, though I'd like to think I'm clever enough to have done so. I have it as an entry in my quotesfile, though unattributed; based on its location in the file, it appears to date from early grad school, so say 1997. It looks like it got added as part of a batch, as I did from time to time back when people forwarded around lists of jokes that were actually funny. That would explain the lack of attribution, as by then I was already being fairly careful to attribute quotes of people I actually recorded myself.
Googling on a slightly less constrained search turns up someone else's quotesfile, who has terrible spelling but includes this quote otherwise identically. And here, it's attributedto one Brian Postow, apparently a CS prof at Union College in Schenectady. Hooray!
Following up this lead, I landed on Postow's own quotes page, which like mine (and probably the other guy's) has its origin in a fortune database, the list of sayings and quotes that you get one of every time you type fortune on older Unix systems. Postow explains this at the top of his page, along with the caveat "Everyone else who isn't otherwise specified was probably a cs major at Oberlin, or a friend of mine from somewhere else... Or, of course some famous type person...".
So, he might not be the source after all. And the really funny part: his own version of the quote does not involve catfish. "Life is just one non sequitur after fruit bat." That page (along with, soon, this one) are the only hits for that formulation. Back to square one.
Continued slogging through Google hits turns up something that may or may not be directly related, but seems promising. Poem CXC in the book 111 2.7.93-10.20.96 by Kenneth Goldsmith ends with the line
...and catfish is a non-sequitur;It was published in 1997, though, and remains somewhat obscure (well, to me), so I'm not totally convinced it would've had time to first morph into the "life is a..." form and then make its way into the geeksphere in time for me to add it to the 'file. It's possible someone familiar with the poem read Postow's fruit bat verson of the line, perceived that catfish would be funnier, and thus modified it. It's possible they're independent.
Or, it could be that non sequiturs and catfish go back a long way. I'm tapped for now; anyone got anything else?
Life is just one non sequitur after catfish. --??
March 21, 2006
For LaTeX help...
I've stumbled across the site before, but didn't bookmark it. The problem is, it doesn't seem to pop to the top of google searches unless you get just the right query, so I keep losing it; and then when I do go looking for something I just end up with yet another mirror of the main LaTeX2e documentation.
So I figured, hey, post it here and it will not only benefit from a smidge more Google karma, but also, I'll be able to search the archives of my blog next time I need it. :)
That's all.
"Worcestershire sauce CURDLES MILK. I had not known that before, but I will not forget. And now you know too. Do not forget!" --Eva Sweeney
February 14, 2006
On websites and usability
Like so many other colleges, Knox suffers from that common disease, crappywebsitis. While the front pages look very pretty, it's always hard to find what you're actually looking for, even if you're part of the "target audience", which is prospective students. Good luck finding a campus map, for instance. It's even worse if you're not in that group. We're in pre-registration season right now, so let's look at the spring course schedules... a minimum of four clicks away from the homepage, and that's if you know where to look.
Map the website over time and the situation gets even worse. The software they use assigns each page a helpful identifier like "x770" (that's for the Knox FAQ, obviously). Make a new page, and it'll get a new identifier. That makes it difficult to bookmark things like "current term course schedule", but it's even worse than that. You can bookmark something like this faculty page (at x2849), and march along happily until someone tells you to look for a link on "the faculty/staff page" that just isn't there. It turns out that it's on this other faculty page (x5875), which is what you get to now if you click "Faculty & Staff" on the main site.
Now here's the kicker: page 5875 has been the "current" faculty and staff page for more than two years now. There is no way to get to 2849 from the main page, as far as I know. But there is no indication on 2849 that it has been superseded by another page, or that page 5875 even exists. And there are things on 2849 that aren't on 5875, and it's easier to use. AND IT'S STILL BEING UPDATED! Look at the right-hand column: those are current events! It's actually a much better page. So I have them both bookmarked.
A big reason the new one is a much worse page is that it violates expectations about how webpages work. Consider this screenshot:
Say you wanted to go to the Registrar. You'd click on the word "Registrar", right? But no, that's just text. You need to click on the header ("ACADEMIC RESOURCES"). That pops up a separate window with a list of a dozen or so links in it, and when you click those links, they close that popup and follow the link in the original window. Broken, broken, broken.
The course schedules are a comparatively un-broken part of the website, once you've found them, and ignoring for a moment the fact that there is a little "TOP" graphic (what, I couldn't find the "home" button?) that manoeuvres itself into the left of the window as you scroll, carefully covering up the titles of the bottom several courses currently visible. The big problem here, though, is that it's just a flat list, and only marginally better than a printed-out copy. There's no easy way to search for "courses offered 6th hour", or "courses that meet the diversity requirement". And there's really no way to search for "courses that don't have any prerequisites", which is important when you're a freshman and have a somewhat limited set of courses available to you. (A lot of courses require "sophomore standing".)
So last year I asked the registrar if I could hook into the database and write my own front end. For security reasons I don't hook in directly, but I get a dump of the course database and process that into a variety of flat viewsstill not searchable (maybe this is a future project!), but at least you can scan through a list that's sorted in various ways. The resulting course schedules have proven very popular both with students and with faculty, and I've kept it up each term. Why are they so popular? Because they don't surprise you with weird interfaces, they don't do anything super-flashy and therefore work just fine even on the ancient machines some people still have running System 8 and Netscape -2 or whatever. And because they actually present information, which is what people are really seeking when they go onto the web, in a way that people can actually use it.
Graphic designers take note: if you're ever called upon to design a website, make sure to take into account a lot more than just the look of the thing.
"Some luck lies in not getting what you thought you wanted, but getting what you have, which, once you have got it, you may be smart enough to see is what you would have wanted had you known." --Garrison Keillor
January 11, 2006
Ok, geek time
I just read the niftiest new thing I've seen in a while. I've hated certain aspects of Java pretty much since it came out in the mid-90s, but for several years now we've known the feature list of Java 1.5, and it addressed my complaints, and threw in a few other nice things that I hadn't complained about, but appreciate the improvement.
So for maybe three years now, I've been raving about Java 1.5 despite not actually being able to write anything in itit's been out quite a while now, but not on all platforms, and general adoption has been slow in some areas. Anyway, in helping a student decide how to implement a certain aspect of his project, I wanted to check out how Java 1.5 implemented the enumerated types I'd heard about.
They're so cool!
The basic enumerated type has been around for decades: in Pascal, for instance, you could say
type Month = (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec); var m: Month; m := May;and this was judged to be cleaner than saying "m := 5" because you couldn't mistake a Month for a Day or a Suit or anything else. However, the identifier May was still really only a fancy name for the number 5 (or perhaps 4); there wasn't anything you got out of it other than readability and type safety. In C, it was really nothing more than a fancy name for a numberyou didn't even get type safety out of the bargain.
So I figured Java's enums were out of this mould, probably more like Pascal than C but still just slightly fancy numbers. No, no, no. Java enums are quite a high-level construct, in fact; while you can treat them like Pascal enums, they can also carry data and behaviours just like any other object. Because in Java, an "enumerated type" is just a class whose instances are all known at compile time. So if you have a limited list of things, like notes on a scale or planets in a solar system or items in a pull-down menu, regardless of how complex those objects are, you get to use an enumerated type.
And a few things come for free when you define an enum, like values() and toString(), which along with the "for-each" loop (another grand new construct in Java 1.5) lets you write stuff like
public enum Suit { SPADES, HEARTS, DIAMONDS, CLUBS }
...
for (Suit s: Suit.values() ) {
System.out.println (s);
}
and it will print out the names of each suit, in order. Nifty, eh?
The Joys of Finnish:
"Kokko, Kokoon koko kokko." ("Kokko, gather together the whole bonfire.")
"Kokoko kokko?" ("The whole bonfire?")
"Koko kokko, Kokko." ("The whole bonfire, Kokko.")
--Eric Dahlman